搜索到
88
篇与
的结果
-
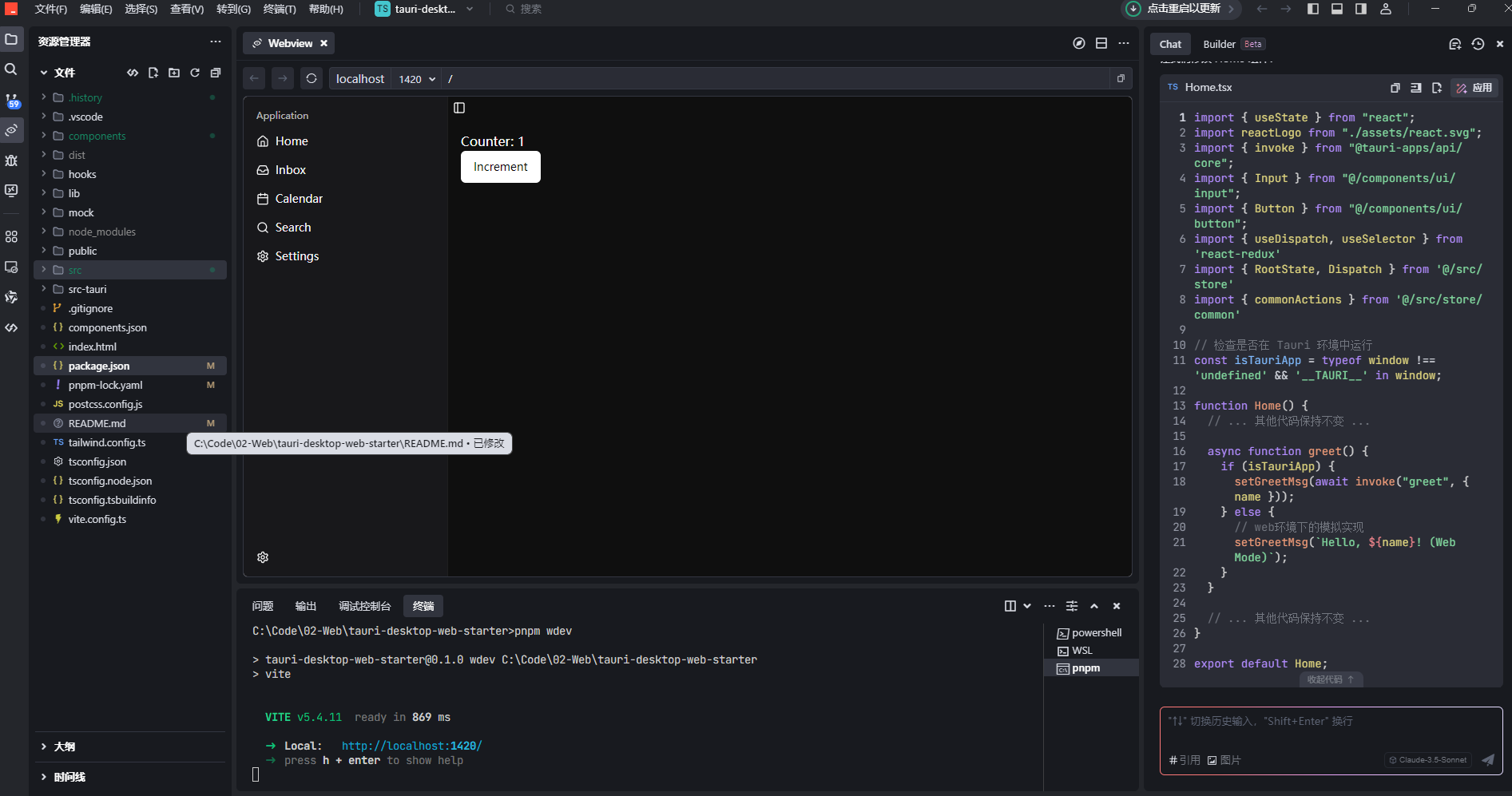
 Tauri2.0尝鲜-正式版脚手架搭建 Tauri 2.0正式版脚手架搭建 Tauri已经迅速成为使用Web技术构建轻量级、安全桌面应用的最受欢迎框架之一。随着Tauri 2.0正式版的发布,现在是探索如何搭建一个生产就绪的脚手架的最佳时机,该脚手架提供了专业桌面应用开发所需的所有工具。 在本文中,我将介绍一个完整的Tauri启动模板,它支持Web和桌面双环境运行,采用现代React + TypeScript技术栈,并包含构建精美、生产就绪应用程序所需的所有基本工具。 为什么选择Tauri 2.0? 在深入探讨我们的脚手架之前,让我们快速回顾一下Tauri 2.0的特点: 更小的打包体积:Tauri应用比Electron替代方案显著更小 增强的安全性:基于Rust的安全原则,采用严格的权限模型 更好的性能:更低的内存消耗和更快的启动时间 多平台支持:从单一代码库为Windows、macOS和Linux构建应用 Web/桌面统一:相同的代码库可以同时作为Web应用和桌面应用运行 随着Tauri 2.0的发布,这些优势得到了增强,包括改进的API、更好的开发体验和更强大的跨平台兼容性。 Tauri桌面Web启动模板介绍 我们将要探索的脚手架为Tauri 2.0应用程序提供了全面的基础。它结合了现代前端技术和Tauri的Rust后端能力,为Web和桌面环境提供了优化的开发体验。 技术栈 我们的启动模板汇集了一流的技术: 核心框架:Tauri 2.0 + Vite + React + TypeScript UI组件:Tailwind CSS + Shadcn UI + Lucide Icons 状态管理:Redux Toolkit 国际化:i18n 后端:Rust 开发工具:用于API模拟的Mock服务 这种组合提供了性能、开发体验和功能完整性的完美平衡。 主要特性 该脚手架具有多项功能,使开发更加顺畅高效: 开箱即用的工程配置:跳过繁琐的设置过程 深色/浅色主题切换:内置主题支持,包括系统主题检测 自定义窗口标题栏:Windows和macOS风格选项 状态管理最佳实践:组织良好的Redux实现 类型安全:完整的TypeScript集成 国际化:开箱即用的多语言支持 Mock数据支持:开发过程中不依赖后端服务 项目结构 了解项目结构对于有效开发至关重要。我们的脚手架遵循清晰合理的组织方式: tauri-desktop-web-starter/ ├── components/ # 公共UI组件 ├── hooks/ # 自定义React Hooks ├── lib/ # 工具库和配置 ├── src/ # 前端源代码 │ ├── assets/ # 静态资源 │ ├── models/ # 数据模型定义 │ ├── pages/ # 页面组件 │ ├── store/ # Redux状态管理 │ │ ├── common/ # 通用状态 │ │ └── index.ts # Store配置 │ ├── translations/ # 国际化文件 │ ├── utils/ # 工具函数 │ │ └── mock/ # Mock服务 │ ├── Home.tsx # 主页组件 │ └── main.tsx # 入口文件 ├── src-tauri/ # Tauri/Rust后端代码 ├── public/ # 公共资源 ├── package.json # 项目依赖配置 ├── postcss.config.js # PostCSS配置 ├── tailwind.config.ts # Tailwind CSS配置 ├── tsconfig.json # TypeScript配置 ├── tsconfig.node.json # Node环境TypeScript配置 └── vite.config.ts # Vite配置 这种组织方式促进了关注点的清晰分离,使应用程序的不同部分易于定位和操作。 开始使用 让我们来看看如何为您自己的项目设置和使用这个脚手架。 环境准备 在开始之前,确保已安装以下工具: Rust:Tauri后端的基础 curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh Node.js:前端JavaScript环境 pnpm:我们选择的包管理器,提供更快、更高效的依赖管理 npm install -g pnpm Tauri CLI:Tauri开发必备 cargo install tauri-cli 开发工作流 安装好先决条件后,可以开始开发: 安装依赖: pnpm install 启动开发服务器: 桌面应用开发: pnpm dev Web开发: pnpm wdev 这种双环境支持允许您在两种环境中开发和测试应用程序。 构建应用程序: 桌面应用打包: pnpm tauri build Web应用构建: pnpm build 功能展示 启动模板开箱即带有精美的UI,包括对不同主题的支持: 浅色主题,提供清晰明亮的界面 深色主题,减少眼睛疲劳,呈现现代美感 系统主题检测,匹配用户偏好 自定义标题栏,符合各操作系统的设计指南 IDE推荐配置 为获得最佳开发体验,我们推荐使用: VS Code 并安装以下扩展: Tauri扩展,增强Tauri开发 rust-analyzer,提供Rust代码智能 这种组合提供了智能代码补全、内联错误检测以及其他特定于Tauri和Rust开发的生产力功能。 自定义和扩展 脚手架设计为易于自定义。以下是您可能想要进行的一些常见自定义: 添加新UI组件:放置在components目录中 创建新页面:添加到src/pages目录 扩展状态管理:向Redux存储添加新的切片 添加Rust功能:使用自定义Rust代码增强src-tauri后端 设置新主题:在Tailwind中修改主题配置
Tauri2.0尝鲜-正式版脚手架搭建 Tauri 2.0正式版脚手架搭建 Tauri已经迅速成为使用Web技术构建轻量级、安全桌面应用的最受欢迎框架之一。随着Tauri 2.0正式版的发布,现在是探索如何搭建一个生产就绪的脚手架的最佳时机,该脚手架提供了专业桌面应用开发所需的所有工具。 在本文中,我将介绍一个完整的Tauri启动模板,它支持Web和桌面双环境运行,采用现代React + TypeScript技术栈,并包含构建精美、生产就绪应用程序所需的所有基本工具。 为什么选择Tauri 2.0? 在深入探讨我们的脚手架之前,让我们快速回顾一下Tauri 2.0的特点: 更小的打包体积:Tauri应用比Electron替代方案显著更小 增强的安全性:基于Rust的安全原则,采用严格的权限模型 更好的性能:更低的内存消耗和更快的启动时间 多平台支持:从单一代码库为Windows、macOS和Linux构建应用 Web/桌面统一:相同的代码库可以同时作为Web应用和桌面应用运行 随着Tauri 2.0的发布,这些优势得到了增强,包括改进的API、更好的开发体验和更强大的跨平台兼容性。 Tauri桌面Web启动模板介绍 我们将要探索的脚手架为Tauri 2.0应用程序提供了全面的基础。它结合了现代前端技术和Tauri的Rust后端能力,为Web和桌面环境提供了优化的开发体验。 技术栈 我们的启动模板汇集了一流的技术: 核心框架:Tauri 2.0 + Vite + React + TypeScript UI组件:Tailwind CSS + Shadcn UI + Lucide Icons 状态管理:Redux Toolkit 国际化:i18n 后端:Rust 开发工具:用于API模拟的Mock服务 这种组合提供了性能、开发体验和功能完整性的完美平衡。 主要特性 该脚手架具有多项功能,使开发更加顺畅高效: 开箱即用的工程配置:跳过繁琐的设置过程 深色/浅色主题切换:内置主题支持,包括系统主题检测 自定义窗口标题栏:Windows和macOS风格选项 状态管理最佳实践:组织良好的Redux实现 类型安全:完整的TypeScript集成 国际化:开箱即用的多语言支持 Mock数据支持:开发过程中不依赖后端服务 项目结构 了解项目结构对于有效开发至关重要。我们的脚手架遵循清晰合理的组织方式: tauri-desktop-web-starter/ ├── components/ # 公共UI组件 ├── hooks/ # 自定义React Hooks ├── lib/ # 工具库和配置 ├── src/ # 前端源代码 │ ├── assets/ # 静态资源 │ ├── models/ # 数据模型定义 │ ├── pages/ # 页面组件 │ ├── store/ # Redux状态管理 │ │ ├── common/ # 通用状态 │ │ └── index.ts # Store配置 │ ├── translations/ # 国际化文件 │ ├── utils/ # 工具函数 │ │ └── mock/ # Mock服务 │ ├── Home.tsx # 主页组件 │ └── main.tsx # 入口文件 ├── src-tauri/ # Tauri/Rust后端代码 ├── public/ # 公共资源 ├── package.json # 项目依赖配置 ├── postcss.config.js # PostCSS配置 ├── tailwind.config.ts # Tailwind CSS配置 ├── tsconfig.json # TypeScript配置 ├── tsconfig.node.json # Node环境TypeScript配置 └── vite.config.ts # Vite配置 这种组织方式促进了关注点的清晰分离,使应用程序的不同部分易于定位和操作。 开始使用 让我们来看看如何为您自己的项目设置和使用这个脚手架。 环境准备 在开始之前,确保已安装以下工具: Rust:Tauri后端的基础 curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh Node.js:前端JavaScript环境 pnpm:我们选择的包管理器,提供更快、更高效的依赖管理 npm install -g pnpm Tauri CLI:Tauri开发必备 cargo install tauri-cli 开发工作流 安装好先决条件后,可以开始开发: 安装依赖: pnpm install 启动开发服务器: 桌面应用开发: pnpm dev Web开发: pnpm wdev 这种双环境支持允许您在两种环境中开发和测试应用程序。 构建应用程序: 桌面应用打包: pnpm tauri build Web应用构建: pnpm build 功能展示 启动模板开箱即带有精美的UI,包括对不同主题的支持: 浅色主题,提供清晰明亮的界面 深色主题,减少眼睛疲劳,呈现现代美感 系统主题检测,匹配用户偏好 自定义标题栏,符合各操作系统的设计指南 IDE推荐配置 为获得最佳开发体验,我们推荐使用: VS Code 并安装以下扩展: Tauri扩展,增强Tauri开发 rust-analyzer,提供Rust代码智能 这种组合提供了智能代码补全、内联错误检测以及其他特定于Tauri和Rust开发的生产力功能。 自定义和扩展 脚手架设计为易于自定义。以下是您可能想要进行的一些常见自定义: 添加新UI组件:放置在components目录中 创建新页面:添加到src/pages目录 扩展状态管理:向Redux存储添加新的切片 添加Rust功能:使用自定义Rust代码增强src-tauri后端 设置新主题:在Tailwind中修改主题配置 -
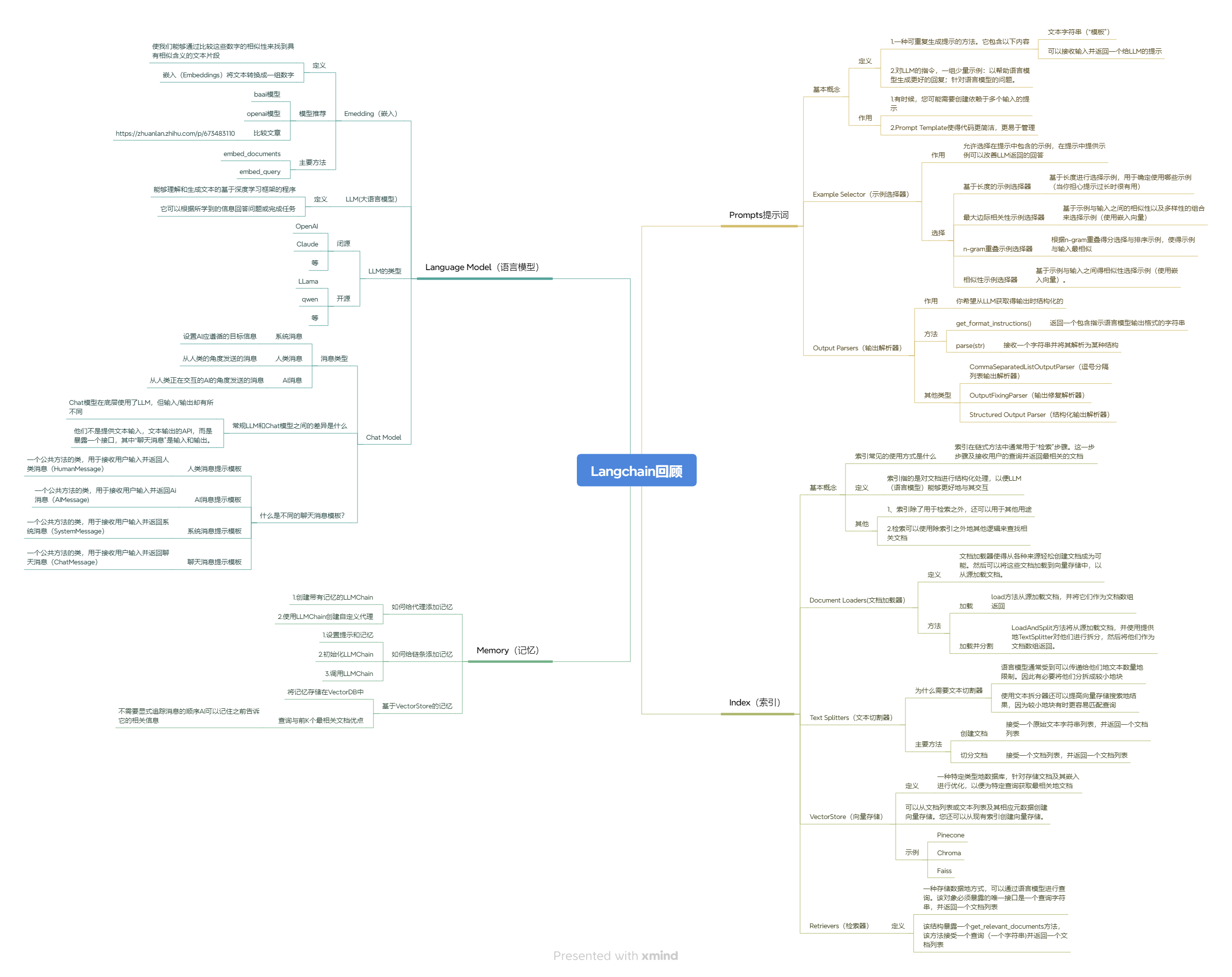
Langchain 回顾 🚀打造 AI 应用的核心利器 Langchain 是一个专为构建基于大语言模型(LLM)的应用而生的强大工具。它将 LLM、向量数据库、记忆机制、提示模板等模块进行了系统整合,大大简化了复杂 AI 应用的开发流程。本文将结合思维导图,对 Langchain 的核心能力做一个全面回顾,并介绍其生态工具 —— LangSmith,让我们能够对 LLM 应用进行高效调试与评估。 🧠 一、Language Model(语言模型) Langchain 提供了对多种主流 LLM 的集成,包括: OpenAI、ChatGLM、Claude、LLaMA、Qwen 等主流模型 支持封装为 LLM、Chat Model 两种类型 提供如 HumanMessage、SystemMessage、AIMessage 等统一结构,构建清晰上下文 支持 Embedding,集成了 text2vec、openai-embeddings 等方案 🧾 二、Prompt 模块(提示词构建) Langchain 封装了 Prompt 构建、示例选择、输出解析等功能: PromptTemplate:参数化构建提示词模板 ExampleSelector:支持基于语义相似度选择 few-shot 示例 Output Parsers:将 LLM 输出转为结构化数据,如 JSON、列表等 🧠 三、Memory(记忆模块) 用于保存对话历史、构建上下文感知的智能体(Agent)系统: 支持 ConversationBufferMemory、SummaryMemory、VectorStoreMemory 等 能力包括短期记忆(会话)与长期记忆(知识) 📚 四、Index 模块(索引与检索) Langchain 提供完整的 RAG 流程: 文档加载(Document Loaders):支持 txt、PDF、Notion、Web 等 文本切分(Text Splitters):如 RecursiveCharacterTextSplitter 向量数据库(Vector Store):支持 FAISS、Chroma、Weaviate 等 检索器(Retriever):封装 .as_retriever() 进行文档查询 🧪 五、LangSmith:Langchain 应用的调试和评估平台 LangSmith 是 Langchain 官方出品的可视化调试与监控平台,专门用于: 🔍 1. 调试链式调用过程 记录每一步链的调用细节 可视化展示 Prompt 输入、输出及 Token 使用情况 支持逐步调试复杂链(Chain)和 Agent 执行流程 📊 2. 性能评估与对比 定义多个 Prompt 模板进行 A/B 测试 自动记录响应时间、成功率、评分等指标 与 OpenAI Function、Tool 使用情况无缝集成 ☁️ 3. 生产环境监控 监控 Agent 的运行行为、失败重试 接入自定义评分函数,对每次调用进行标注 ✨ 总结一句话: LangChain 让你快速构建 LLM 应用,LangSmith 让你安心上线并优化它。 🧩 六、应用场景示例 聊天机器人 / 客服系统 企业文档问答 / 私人知识库 表单解析 / 结构化信息提取 智能搜索系统(结合向量检索) Prompt 模板测试平台(结合 LangSmith) 一个比较完整的python demo实现 #langsmith 的key #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 import os os.environ['USER_AGENT'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3' from langchain_community.llms import Ollama from langchain import hub from langchain.agents import create_openai_functions_agent from langchain.agents import AgentExecutor from langchain_core.messages import HumanMessage, AIMessage from langchain_community.vectorstores import FAISS from langchain_community.document_loaders import WebBaseLoader from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain.tools.retriever import create_retriever_tool from langchain_community.tools.tavily_search import TavilySearchResults from langchain_ollama import OllamaEmbeddings from langchain_ollama import OllamaLLM # from langchain.pydantic_v1 import BaseModel, Field from pydantic import BaseModel, Field from fastapi import FastAPI from typing import List from langserve import add_routes from langchain_core.messages import BaseMessage ### 1.加载检索器 loader = WebBaseLoader("https://docs.smith.langchain.com/user_guide") docs = loader.load() text_splitter = RecursiveCharacterTextSplitter() documents = text_splitter.split_documents(docs) embeddings = OllamaEmbeddings(base_url="http://172.16.1.27:11434", model="nomic-embed-text:latest") vector = FAISS.from_documents(docs,embeddings) retriever = vector.as_retriever() ### 2. 创建工具 retriever_tool = create_retriever_tool( retriever, "langsmith_search", "搜索与LangSmith相关的信息。有关LangSmith的任何问题,您必须使用此工具!", ) search = TavilySearchResults() tools = [retriever_tool, search] ### 3.创建代理人 # 加载模型 llama = OllamaLLM(model="llama3.2-vision:latest",base_url="http://172.16.1.27:11434") # 获取要使用的提示 - 您可以修改此提示! prompt = hub.pull("hwchase17/openai-functions-agent") agent = create_openai_functions_agent(llama, tools, prompt) agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True) # 4. 应用程序定义 app = FastAPI( title="LangChain服务器", version="1.0", description="使用LangChain的可运行接口的简单API服务器", ) # 5. 添加链路由 class Input(BaseModel): input: str chat_history: List[BaseMessage] = Field( ..., extra={"widget": {"type": "chat","input":"location"}}, ) class Output(BaseModel): output: str add_routes(app, agent_executor.with_types(input_type=Input, output_type=Output), path="/agent") if __name__ == "__main__": import uvicorn uvicorn.run(app, host="localhost", port=8000) 🧷 七、总结 Langchain 是构建大模型应用的主干框架,围绕核心模块 —— Prompt、Memory、Index、LLM,打通了从数据到生成的全链路。而 LangSmith 则作为配套工具,填补了 调试、测试、监控 的空白,帮助我们更好地构建可信的 AI 应用。 好的!既然你希望对比 Langchain + LangSmith 与其它技术方案,那我们可以从几个维度来做一个 横向对比分析,让你的博客不仅回顾 Langchain,还凸显它的优势和适用场景。 🧭 Langchain 与其他 LLM 应用框架的对比分析 在构建 LLM 应用时,除了 Langchain,还有不少热门的框架和工具,比如: 框架名称 核心特点 是否组件化 是否支持 Agent 调试能力 主打场景 Langchain 模块化封装 Prompt、Memory、索引、Agent ✅ ✅ ✅(搭配 LangSmith) RAG、ChatBot、Agent LlamaIndex 强调数据索引能力,集成多种文档加载/拆分方式 ✅ ⚠️(基础 Agent 支持) ❌ 文档问答、知识库 Haystack 企业级搜索和问答,支持自定义 Pipeline ✅ ✅ ✅(较重配置) 企业内部搜索、QA Autogen (MS) 多 Agent 协作框架,适合任务分工 ⚠️(较弱) ✅(核心) ❌(需配合日志) Agent 协作系统 Flowise 可视化 Langchain,拖拽式搭建 ✅(UI) ✅(底层用 Langchain) ✅(UI可视化) 快速原型、低代码 🔍 详细维度分析 1. 开发体验 对比项 Langchain LlamaIndex Haystack Autogen Flowise 上手难度 中(模块较多) 低(专注文档检索) 中高(配置多) 高(偏研究) 低(拖拽) 模块化 ✅ ✅ ✅ ⚠️ ✅ 类型支持 文档问答、对话、Agent 文档问答 QA Pipeline 多智能体任务 Chat/RAG 📌 如果你要构建复杂的 AI 应用,Langchain 的模块化设计 + LangSmith 调试工具,开发体验更全面。 2. 文档问答能力(RAG 架构支持) 对比项 Langchain LlamaIndex Haystack 向量索引支持 ✅(多种 VectorStore) ✅ ✅ 文档加载丰富度 ✅ ✅ ✅ 拆分策略 丰富(Recursive、Token等) 丰富 主要基于段落 多源融合 ✅ ✅ ✅ 检索方式灵活性 高(自定义 Retriever) 中 中 📌 Langchain 与 LlamaIndex 都支持强大的 RAG,Langchain 更适合自定义 Agent 与对话流整合。 3. Agent 能力对比 对比项 Langchain Agent Autogen Haystack 多工具调用 ✅ ✅ ✅(较少) 工具链整合 ✅(Tool/Toolkits) ✅(需自建 Tool) ⚠️ 多 Agent 协作 ✅(Router Chain) ✅(核心能力) ❌ 日志追踪 ✅(配合 LangSmith) ❌ ✅(基本) 📌 如果你是搞 Agent 系统的,Autogen 适合多智能体协作研究,但 Langchain 更适合落地和定制。 4. 调试与监控(LangSmith 优势突显) 框架 是否支持可视化调试 是否支持运行监控 自定义评分支持 是否 SaaS 服务 Langchain + LangSmith ✅ ✅ ✅ ✅(LangSmith 平台) LlamaIndex ❌ ❌ ❌ ❌ Haystack 部分 部分 需手动配置 ❌ Autogen ❌(手工打印) ❌ ❌ ❌ 📌 LangSmith 是目前 最适合 LLM 应用调试的可视化平台,对链条调用非常透明。 ✅ 总结:我该选谁? 你想快速构建实用型 AI 应用(问答、客服、Agent):用 Langchain + LangSmith 你只想搞定文档问答系统:可以考虑 LlamaIndex 你有企业级搜索需求:考虑 Haystack 你研究智能体协作:玩玩 Autogen 你是产品经理或低代码开发者:试试 Flowise
-
基于 Taro 技术栈搭建的跨端客户端脚手架 基于 Taro 技术栈搭建的跨端客户端脚手架 一、项目背景 接手的项目各个技术栈不同,有原生微信小程序,有flutter开发的客户端,有uniapp开发的客户端,现在想统一技术栈,为什么选择Taro不是uniapp,主要是因为ReactNative。 二、技术栈选型 Taro 3.x:京东凹凸实验室开源的跨端开发框架 React 18:用于构建用户界面的 JavaScript 库 TypeScript:添加了类型系统的 JavaScript 超集 NutUI:京东风格的轻量级移动端组件库 Redux Toolkit:Redux 官方推荐的工具集 Pnpm:高性能的包管理工具 三、项目结构设计 ├── config # 项目配置文件 │ ├── dev.js # 开发环境配置 │ ├── index.js # 基础配置 │ └── prod.js # 生产环境配置 ├── src # 源码目录 │ ├── api # API 接口 │ ├── assets # 静态资源 │ ├── components # 公共组件 │ ├── constants # 常量定义 │ ├── models # 模型定义 │ ├── hooks # 自定义 Hooks │ ├── pages # 页面文件 │ ├── service # 业务处理 │ ├── store # 状态管理 │ ├── types # TypeScript 类型定义 │ ├── utils # 工具函数 │ └── app.tsx # 应用入口 四、关键技术实现 1. 多端适配策略 // 条件编译示例 import { Platform } from '@tarojs/service' // #ifdef WEAPP console.log('微信小程序环境') // #endif // #ifdef TT console.log('抖音小程序环境') // #endif 2. 状态管理方案 // store/index.ts import { configureStore } from '@reduxjs/toolkit' import userReducer from './slices/user' export const store = configureStore({ reducer: { user: userReducer } }) 3. 网络请求封装 // utils/request.ts import Taro from '@tarojs/taro' const request = async (options) => { try { const response = await Taro.request({ url: BASE_URL + options.url, method: options.method, data: options.data, header: { 'content-type': 'application/json', ...options.header } }) return response.data } catch (error) { console.error('请求错误:', error) throw error } } 五、最佳实践与注意事项 1. 组件库使用规范 NutUI 图标组件引入顺序问题 // ✅ 正确示例 import { ArrowRight } from '@nutui/icons-react-taro' import { Button } from '@nutui/nutui-react-taro' // ❌ 错误示例 import { Button } from '@nutui/nutui-react-taro' import { ArrowRight } from '@nutui/icons-react-taro' 2. 平台差异处理 抖音小程序 AbortController 兼容性问题 微信小程序热重载配置注意事项 3.注意点 如果报如下警告 despite it was not able to fulfill desired ordering with these modules: * css ./node_modules/.pnpm/css-loader@7.1.2_webpack@5.78.0_@swc+core@1.3.96_/node_modules/css-loader/dist/cjs.js ??ruleSet[1].rules[4].oneOf[0] .use[1]!./node_modules/.pnpm/postcss-loader@8.1.1_postcss@8.4.49_typescript@5.7.3_webpack@5.78.0_@swc+core@1.3.96_/node_modules/postcss-loader/dist/cjs.js ??ruleSet[1].rules[4].oneOf[0] .use[2]!./node_modules/.pnpm/@nutui+icons-react-taro@2.0.1/node_modules/@nutui/icons-react-taro/dist/style_icon.css - couldn't fulfill desired order of chunk group(s) pages/user/index - while fulfilling desired order of chunk group(s) pages/index/index, pages/category/index, pages/order/index 原因是 import { ArrowRight } from '@nutui/icons-react-taro' import引入顺序有问题,因为在这个语句的前面有引入其他的组件,其他的组件里也使用了@nutui/icons-react-taro,所以会报这个警告,只需要把import { ArrowRight } from '@nutui/icons-react-taro'放到最前面就可以了。 4.坑点 taro的mock插件没有适配最新版,不能新建mock目录,已经适配了最新版的插件可自行编译https://github.com/javajeans/taro-plugin-mock 六、构建与部署 # 安装依赖 pnpm install # 开发环境 pnpm dev:weapp # 微信小程序 pnpm dev:tt # 抖音小程序 pnpm dev:h5 # H5 # 生产环境 pnpm build:weapp pnpm build:tt pnpm build:h5 七、性能优化建议 合理使用条件编译 组件按需加载 图片资源压缩 避免不必要的重渲染 八、总结 通过 Taro 技术栈,我们成功搭建了一套可维护、可扩展的跨端开发脚手架。该脚手架具有以下特点: 统一的开发体验 完善的工程化配置 规范的代码风格 丰富的组件库支持 灵活的状态管理
-
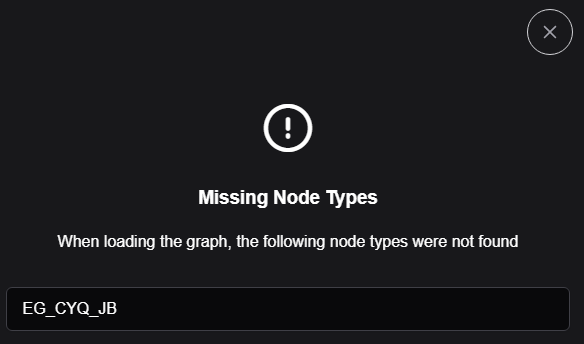
ComfyUI 使用笔记 ComfyUI 使用笔记 Reactor 换脸 ComfyUI-GIMM-VFI节点运行异常问题解决 节点用的是旧版本的torch的sdk,报这个错,作者还未修改 AttributeError: module 'torch.amp' has no attribute 'custom_fwd' 需要修改节点代码目录ComfyUI-GIMM-VFI\gimmvfi\generalizable_INR\modules\softsplat.py文件的第361行改成如下 @torch.cuda.amp.custom_fwd(cast_inputs=torch.float32) 和452行改成 @torch.cuda.amp.custom_bwd 安装CLIPSeg 报错 ## install failed: With the current security level configuration, only custom nodes from the **"default channel"** can be installed. 解决方式: 更新ComfyUI-Manager插件即可 参考https://github.com/comfyanonymous/ComfyUI_TensorRT/issues/6 缺少EG_CYQ_JB节点 进入custom_nodes节点目录,执行 git clone https://github.com/11dogzi/Comfyui-ergouzi-DGNJD.git 手动拉去插件 参考https://openart.ai/workflows/tdlong189/flux-and-sd15-anime-to-real-photo/OMN6addlGc9qiSgaDsj5 命令行下载 huggingface-cli download black-forest-labs/FLUX.1-Depth-dev-lora --include "*.safetensors" --local-dir flux_comfyui --token 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 使用OmniGen报异常 RuntimeError: Failed to import OmniGen. Please check if the code was downloaded correctly. 解决: A:\ComfyUI_windows_portable\python_embeded\python.exe" -m pip uninstall diffusers A:\ComfyUI_windows_portable\python_embeded\python.exe" -m pip install diffusers==0.30.3 A:\ComfyUI_windows_portable\python_embeded\python.exe" -m pip install peft==0.13.2 python.exe -m pip install timm -i https://pypi.tuna.tsinghua.edu.cn/simple https://github.com/AIFSH/OmniGen-ComfyUI/issues 安装 error: command 'cl.exe' failed: None [end of output] note: This error originates from a subprocess, and is likely not a problem with pip. ERROR: Failed building wheel for insightface 解决方式: 安装vs2022 配置环境 一、在哪里配置 配置的地方呢就是在 控制面板的用户账户里面的用户账户,话不多说,上图! 1).打开控制面板 2).找到用户账户 3).找到更改我的环境变量 4).最终路径 二、开始配置 1)、总体步骤 总体步骤是:首先path里面添加路径,然后新建include变量添加相关路径,接着新建bin变量添加相关路径,最后点击确定添加完成! 2)、配置步骤 1.Path变量的操作 先在 ***的用户变量 里面找到 Path; 然后双击或者点击编辑; 接着找到自己的Visual Studio的安装路径(桌面图标,右键,打开文件所在位置,然后找到主路径,如图) 这是打开文件所在位置后定位到的路径: D:\Visual Studio\Program Files\2022\Community\Common7\IDE 在IDE文件夹里面,devenv.exe就是我们的IDE软件, 接下来下一步,找到主路径,往上走两个文件夹,定位到 D:\Visual Studio\Program Files\2022\Community Community是我安装的Visuai Studio版本为社区版,如果是专业版就应该是Professional文件夹, 前面的 D:\Visual Studio\Program Files\2022只是我安装的路径,这就是为什么使用打开文件所在位置来定位文件路径,这样的话可以避免大家的安装位置不一样而导致这个教程不适用,一般来说无论安装在哪里,都会有一个Community或者Professional又或者Enterprise文件夹; 然后一次点击文件夹VC、Tools、MSVC、14.31.31103、bin、Hostx64、x64,定位到路径: D:\Visual Studio\Program Files\2022\Community\VC\Tools\MSVC\14.31.31103\bin\Hostx64\x64 注意文件夹14.31.31103大家的可能会不一样,但是没关系,都是一串数字,然后将下图蓝色的文件路径复制到粘贴板; 最后回到环境变量双击Path的界面,点击新建,输入复制的文件路径,回车,确认即可,如图: 2.include变量操作 先寻找文件路径,还是刚才的D:\Visual Studio\Program Files\2022\Community路径,接下来 依次点击VC、Tools、MSVC、14.31.31103、include文件夹,定位到 D:\Visual Studio\Program Files\2022\Community\VC\Tools\MSVC\14.31.31103\include 这个路径,注意14.31.31103还是会不一样,但是仍旧是一串数字的那个文件夹, 然后在用户变量里面新建环境变量,把上面的路径输入,在后面加上冒号;(英文输入法,下同) D:\Visual Studio\Program Files\2022\Community\VC\Tools\MSVC\14.31.31103\include 然后定位到 Windows Kits 文件夹,如果你把应用装在D盘,你就会在D盘找到D:\Windows Kits路径,而如果你的应用在C盘那就再路径C:\Program Files (x86)会有一个Windows Kits文件夹,这里以路径D:\Windows Kits为例,找到路径D:\Windows Kits\10\Include\10.0.19041.0,将文件夹10.0.19041.0里面的cppwinr和shared和ucrt和um和winrt五个文件夹的路径依次添加到刚刚新建的INCLUDE环境变量下, D:\Windows Kits\10\Include\10.0.19041.0\cppwinr D:\Windows Kits\10\Include\10.0.19041.0\shared D:\Windows Kits\10\Include\10.0.19041.0\ucrt D:\Windows Kits\10\Include\10.0.19041.0\um D:\Windows Kits\10\Include\10.0.19041.0\winrt 所有的路径如下,总共是6个 (注意路径之间的分号)如下图: 点击确定后双击INCLUDE查看如下图: 点击确定就完成了include的环境变量配置; 3.lib环境变量配置 同样,再建一个LIB环境变量,还是先寻找文件路径,而且还是刚才的D:\Visual Studio\Program Files\2022\Community路径,接下来 依次点击VC、Tools、MSVC、14.31.31103、lib文件夹,定位到D:\Visual Studio\Program Files\2022\Community\VC\Tools\MSVC\14.31.31103\lib\x64路径,注意14.31.31103还是会不一样,但是仍旧是一串数字的那个文件夹,然后在用户变量里面新建环境变量,把上面的路径输入,在后面加上冒号(英文输入法下的冒号 ; ) 然后定位到 Windows Kits 文件夹,如果你把应用装在D盘,你就会在D盘找到D:\Windows Kits路径,而如果你的应用在C盘那就再路径C:\Program Files (x86)会有一个Windows Kits文件夹,这里以路径D:\Windows Kits为例,找到路径D:\Windows Kits\10\Include\10.0.19041.0,将文件夹10.0.19041.0里面的ucrt和ucrt_enclave和um三个文件夹下面的x64文件夹路径依次添加到新建的LIB环境变量里面, D:\Windows Kits\10\Lib\10.0.19041.0\ucrt\x64 D:\Windows Kits\10\Lib\10.0.19041.0\ucrt_enclave\x64 D:\Windows Kits\10\Lib\10.0.19041.0\um\x64 注意路径间的分号,然后点击确定,查看如下图: 到此为止,建立完毕,点击确定完成环境变量的配置! win+r输入cmd打开命令提示符窗口,输入cl,出现下图则配置成功, 三、测试 在桌面右键创建一个txt文本文件,修改名称为test.c(.c是后缀),就得到一个C格式文件,双击打开,写入代码: #include <stdio.h> #include <stdlib.h> int main() { printf("hello world!"); return 0; } 保存 win+r输入cmd打开命令提示符窗口,输入cd desktop定位到test.c所在的桌面路径, 输入cl /EHsc test.c,回车,会生成.obj文件和.exe可执行文件: 接着输入test就会生成打印 hello world! 测试完毕! 参考https://blog.csdn.net/2301_79301617/article/details/134175538 参考https://blog.csdn.net/en_Wency/article/details/124767742 视频嘴型同步 视频帧率有要求 语音频率有要求 原生版本节点依赖安装 python.exe -m pip install f5_tts -i https://pypi.tuna.tsinghua.edu.cn/simple 模型国内源配置 这里我会针对ComfyUI讲一种简单的方法,修改python库huggingface_hub。以下是具体操作步骤: 在 python_embeded\Lib\site-packages\huggingface_hub 目录下,找到__init__.py文件,右键点击编辑打开它,在最后一行加上 os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' 然后保存文件即可!
-
Pytorch学习笔记 训练模型数据集划分 数据集通常会被划分为训练集(Training Set)、验证集(Validation Set)和测试集(Test Set),这样可以有效地训练、优化和评估模型的性能。 1. 训练集(Training Set) 作用:用于模型的学习,即让模型调整参数(权重和偏置)。 占比:一般占 60%-80% 的总数据。 细节:模型在这个数据集上不断计算损失 → 反向传播 → 更新参数,以最小化误差。 2. 验证集(Validation Set) 作用:在训练过程中监测模型的表现,用于调整超参数(如学习率、层数、神经元数量等),防止过拟合。 占比:一般占 10%-20% 的总数据。 细节: 训练过程中不会对验证集进行梯度更新,仅用于计算指标(如准确率、损失)。 用于超参数调优,选择最优模型配置。 3. 测试集(Test Set) 作用:在模型完全训练好后,用于最终评估模型的泛化能力。 占比:一般占 10%-20% 的总数据。 细节: 不能用于训练,也不能用于超参数调优,完全独立。 反映模型对未见过的数据的表现,确保模型不会仅仅记住训练数据(过拟合)。 为什么要区分验证集和测试集? 很多人会问:“为什么不直接用测试集来调优超参数?” 原因: 如果我们用测试集来调整超参数,模型就会对测试集产生信息泄露,测试集就不再是真正的未知数据,评估结果会有偏差。 验证集的作用是提供反馈,而测试集的作用是提供最终评分。 数据集划分方法 1. 直接划分 from sklearn.model_selection import train_test_split # 生成示例数据 X = [[i] for i in range(1000)] # 1000 个样本 y = [i % 2 for i in range(1000)] # 二分类标签 # 先划分为训练集 + 剩余集(80% 训练,20% 剩余) X_train, X_rem, y_train, y_rem = train_test_split(X, y, test_size=0.2, random_state=42) # 再划分验证集和测试集(各 10%) X_val, X_test, y_val, y_test = train_test_split(X_rem, y_rem, test_size=0.5, random_state=42) print(f"训练集大小: {len(X_train)}, 验证集大小: {len(X_val)}, 测试集大小: {len(X_test)}") 输出: 训练集大小: 800, 验证集大小: 100, 测试集大小: 100 2. K 折交叉验证(适用于小数据集) 如果数据集较小,可以使用 K 折交叉验证(K-Fold Cross Validation): from sklearn.model_selection import KFold import numpy as np X = np.array(range(100)) kf = KFold(n_splits=5, shuffle=True, random_state=42) # 5 折交叉验证 for train_index, val_index in kf.split(X): print(f"训练集: {train_index}, 验证集: {val_index}") 总结 数据集 作用 是否参与训练 用于超参数调优 何时使用 训练集 训练模型 ✅ ❌ 训练时 验证集 调整超参数,监测过拟合 ❌ ✅ 训练过程中 测试集 评估最终性能 ❌ ❌ 训练结束后 🚀 最佳实践: ✅ 80%-10%-10% 划分(训练-验证-测试) ✅ K 折交叉验证(当数据较少时) 神经网络模型训练的原理 神经网络模型训练的本质是一个 优化过程,核心目标是 最小化损失函数(Loss Function),使得模型对训练数据的预测尽可能准确。训练过程主要包括 前向传播(Forward Propagation)、损失计算(Loss Calculation)、反向传播(Backward Propagation)、参数更新(Parameter Update) 四个关键步骤。 1. 前向传播(Forward Propagation) 计算从输入到输出的结果 输入数据 ( X ) 经过 加权求和 和 激活函数 处理,得到 预测值 ( Y_{\text{pred}} )。 数学公式: [ Z = W \cdot X + b ] [ Y_{\text{pred}} = \sigma(Z) ] 其中: ( W ) 是 权重(Weights) ( b ) 是 偏置(Bias) ( \sigma(Z) ) 是 激活函数(如 ReLU、Sigmoid) 2. 计算损失函数(Loss Calculation) 衡量模型的预测值与真实值之间的差距 损失函数(Loss Function) 用来量化误差,常见损失函数: 回归任务(预测连续值):使用 均方误差(MSE) [ L = \frac{1}{N} \sum (Y_{\text{true}} - Y_{\text{pred}})^2 ] 分类任务(预测类别):使用 交叉熵损失(CrossEntropy) [ L = -\sum Y_{\text{true}} \log(Y_{\text{pred}}) ] 3. 反向传播(Backward Propagation) 计算梯度,调整参数 通过 链式求导法则(Chain Rule) 计算每个参数对损失函数的贡献: [ \frac{\partial L}{\partial W} ] 反向传播的本质是 梯度下降(Gradient Descent): [ W = W - \alpha \cdot \frac{\partial L}{\partial W} ] 其中: ( \alpha ) 是 学习率(Learning Rate) ( \frac{\partial L}{\partial W} ) 是 梯度(Gradient) 4. 参数更新(Parameter Update) 使用优化算法(如 SGD、Adam)调整权重,使损失减少: 随机梯度下降(SGD): [ W = W - \alpha \cdot \frac{\partial L}{\partial W} ] Adam(自适应学习率优化) 计算梯度的指数加权平均 适用于 非平稳数据和稀疏梯度 完整示例:用 PyTorch 训练神经网络 import torch import torch.nn as nn import torch.optim as optim # 1. 准备数据 X = torch.tensor([[1.0], [2.0], [3.0], [4.0]]) # 输入 Y = torch.tensor([[2.0], [4.0], [6.0], [8.0]]) # 真实值 # 2. 构建模型 class LinearRegressionModel(nn.Module): def __init__(self): super().__init__() self.linear = nn.Linear(1, 1) # 一层线性回归模型(y = Wx + b) def forward(self, x): return self.linear(x) model = LinearRegressionModel() # 3. 选择损失函数和优化器 loss_fn = nn.MSELoss() # 均方误差 optimizer = optim.SGD(model.parameters(), lr=0.01) # 4. 训练模型 for epoch in range(100): Y_pred = model(X) # 前向传播 loss = loss_fn(Y_pred, Y) # 计算损失 optimizer.zero_grad() # 清除梯度 loss.backward() # 反向传播 optimizer.step() # 参数更新 if (epoch + 1) % 10 == 0: print(f'Epoch {epoch+1}, Loss: {loss.item():.4f}') # 5. 预测新数据 new_X = torch.tensor([[5.0]]) predicted_Y = model(new_X).item() print(f"预测 5 对应的值: {predicted_Y:.2f}") 总结 步骤 说明 前向传播 计算从输入到输出的预测值 计算损失 计算预测值与真实值的误差 反向传播 计算梯度,优化参数 参数更新 使用梯度下降调整权重 在 PyTorch 中,梯度下降(Gradient Descent)是优化模型参数的核心方法之一。PyTorch 提供了 torch.optim 模块,其中包含了多种优化算法,包括最基本的 随机梯度下降(SGD),以及更高级的优化算法(如 Adam、RMSprop 等)。 1. PyTorch 梯度下降的基本流程 梯度下降的核心步骤如下: 前向传播(Forward Propagation) 计算损失函数(Loss)。 反向传播(Backward Propagation) 计算梯度,即对参数求导。 更新参数(Parameter Update) 使用优化器(如 SGD)更新模型参数。 2. PyTorch 实现梯度下降 (1) 使用 torch.optim.SGD import torch # 创建模型参数(需要计算梯度) w = torch.tensor(2.0, requires_grad=True) # 定义损失函数 L = (w-3)² def loss_fn(w): return (w - 3) ** 2 # 定义优化器(学习率 lr=0.1) optimizer = torch.optim.SGD([w], lr=0.1) # 梯度下降迭代 for i in range(10): loss = loss_fn(w) # 计算损失 optimizer.zero_grad() # 清空梯度 loss.backward() # 计算梯度 optimizer.step() # 更新参数 print(f"Step {i+1}: w = {w.item()}, Loss = {loss.item()}") 流程解析 optimizer.zero_grad(): 清空梯度,避免梯度累积。 loss.backward(): 计算损失对 w 的梯度 ∂L/∂w。 optimizer.step(): 使用 SGD 更新参数: [ w = w - \text{lr} \times \frac{\partial L}{\partial w} ] (2) 手动实现梯度下降 如果不使用 torch.optim,可以手动更新参数: w = torch.tensor(2.0, requires_grad=True) lr = 0.1 # 学习率 for i in range(10): loss = loss_fn(w) # 计算损失 loss.backward() # 计算梯度 with torch.no_grad(): # 关闭梯度计算,防止 PyTorch 记录计算图 w -= lr * w.grad # 参数更新 w.grad.zero_() # 清空梯度 print(f"Step {i+1}: w = {w.item()}, Loss = {loss.item()}") 这里手动计算 w -= lr * w.grad,效果等同于 optimizer.step()。 3. PyTorch 支持的优化算法 除了 SGD,PyTorch 还提供了更高级的优化器: Adam (torch.optim.Adam):适用于大多数任务,收敛快。 RMSprop (torch.optim.RMSprop):适用于非平稳目标函数(如强化学习)。 Adagrad (torch.optim.Adagrad):适用于稀疏数据。 示例(使用 Adam): optimizer = torch.optim.Adam([w], lr=0.1) 4. 选择合适的梯度下降算法 优化器 适用场景 主要特点 SGD 经典梯度下降 适用于凸优化,学习率难以调整 SGD + Momentum 加速收敛 可减少振荡,适用于深度网络 Adam 通用 结合了 RMSprop 和 Momentum,适用性强 RMSprop 适用于非平稳目标 适用于强化学习和递归神经网络 Adagrad 适用于稀疏数据 适合 NLP 任务,梯度会逐渐减小 在深度学习任务中,Adam 是默认的首选优化器。 5. 结论 梯度下降是优化模型的核心方法,PyTorch 提供了自动求导和优化器。 使用 torch.optim 可以方便地管理优化算法,如 SGD 和 Adam。 对于深度学习任务,Adam 通常是更好的选择。