搜索到
9
篇与
的结果
-
 Codex Cli Windows下 乱码问题处理 Codex Cli Windows下 乱码问题处理 步骤 1、新建脚本 Setup UTF-8 PowerShell Environment # Setup UTF-8 PowerShell Environment chcp 65001 | Out-Null [Console]::InputEncoding = [System.Text.UTF8Encoding]::new() [Console]::OutputEncoding = [System.Text.UTF8Encoding]::new() $OutputEncoding = [System.Text.UTF8Encoding]::new() $PSDefaultParameterValues['Out-File:Encoding'] = 'utf8' $PSDefaultParameterValues['Set-Content:Encoding'] = 'utf8' $PSDefaultParameterValues['Add-Content:Encoding'] = 'utf8' Write-Host "PowerShell UTF-8 environment configured successfully." 命名为Setup-UTF8PowerShell.ps1保存到目录 2、打开目录和打开powershell窗口 执行改脚本 ./Setup-UTF8PowerShell.ps1 执行codex 测试下 如果报如下错误 在powershell会报codex : 无法加载文件 C:\Program Files\nodejs\codex.ps1,因为在此系统上禁止运行脚本。有关详细信息,请参阅 https:/go.microsoft.com/fwlink/?LinkID=135170 中的 ab out_Execution_Policies。 所在位置 行:1 字符: 1 + codex + ~~~~~ + CategoryInfo : SecurityError: (:) [],PSSecurityException + FullyQualifiedErrorId : UnauthorizedAccess 在powershell窗口执行 Set-ExecutionPolicy -Scope CurrentUser RemoteSigned
Codex Cli Windows下 乱码问题处理 Codex Cli Windows下 乱码问题处理 步骤 1、新建脚本 Setup UTF-8 PowerShell Environment # Setup UTF-8 PowerShell Environment chcp 65001 | Out-Null [Console]::InputEncoding = [System.Text.UTF8Encoding]::new() [Console]::OutputEncoding = [System.Text.UTF8Encoding]::new() $OutputEncoding = [System.Text.UTF8Encoding]::new() $PSDefaultParameterValues['Out-File:Encoding'] = 'utf8' $PSDefaultParameterValues['Set-Content:Encoding'] = 'utf8' $PSDefaultParameterValues['Add-Content:Encoding'] = 'utf8' Write-Host "PowerShell UTF-8 environment configured successfully." 命名为Setup-UTF8PowerShell.ps1保存到目录 2、打开目录和打开powershell窗口 执行改脚本 ./Setup-UTF8PowerShell.ps1 执行codex 测试下 如果报如下错误 在powershell会报codex : 无法加载文件 C:\Program Files\nodejs\codex.ps1,因为在此系统上禁止运行脚本。有关详细信息,请参阅 https:/go.microsoft.com/fwlink/?LinkID=135170 中的 ab out_Execution_Policies。 所在位置 行:1 字符: 1 + codex + ~~~~~ + CategoryInfo : SecurityError: (:) [],PSSecurityException + FullyQualifiedErrorId : UnauthorizedAccess 在powershell窗口执行 Set-ExecutionPolicy -Scope CurrentUser RemoteSigned -
用AI生成的原型设计稿效果还可以 用AI生成的原型设计稿效果还可以 提示词如下 # 主界面布局 ## 整体结构 - **简洁的双栏式布局**:左侧窄导航栏、右侧宽内容区 - **顶部标题栏**:包含应用图标和最小化/最大化/关闭按钮 - **底部帮助按钮**:提供快速访问支持资源 ## 左侧导航栏 - **垂直排列的四个主要功能图标**:会议、人声、串联、设置(底部为帮助按钮) - **每个图标配有简洁文字标签** - **采用简约图标设计**,突出功能识别度 - **当前选中的功能以高亮状态显示** --- ## 功能区块设计 ### 1. 会议记录区域 #### 文件导航子菜单 - 位于左侧导航栏右侧,展示分类文件夹 - 包含四个主要选项: - **最近文件** - **我的文件** - **收藏文件** - **垃圾箱** - 每个选项配有直观图标,点击后在主内容区显示对应内容 #### 主内容区文件列表 - **顶部功能区**: - **开始录音按钮** - **上传音频按钮** - **搜索框** - **表格式文件列表**,包含列标题: - 名称 - 类型 - 时长 - 创建时间 - 操作 - **空白状态** 显示提示信息和操作建议 - **列表支持排序和筛选功能** --- ### 2. 录音/会议详情视图 - 点击 **"开始录音"** 后转换为录音界面,显示 **波形图和实时转写内容** - **会议详情页面** 分为上下两部分: - **音频控制** - **文本转写** - **按发言人分色显示转写文本** - **右侧工具栏** 提供: - **编辑** - **导出** - **分享功能** --- ## 视觉规范 ### 色彩系统 - **主色**:`#2B5BFF`(品牌蓝) - **辅助色**:`#F5F7FA`(背景灰) - **文字色**: - 主要文字:`#1D2129` - 次要文字:`#4E5969` - 说明文字:`#86909C` - **边框色**:`#E5E6EB` - **分割线**:`#E5E6EB` - **背景色**: - **主背景**:`#FFFFFF` - **次要背景**:`#F5F7FA` ### 字体规范 #### 标题 - **H1**:20px, Medium - **H2**:18px, Medium - **H3**:16px, Medium #### 正文 - **主要文字**:14px, Regular - **次要文字**:13px, Regular - **辅助文字**:12px, Regular --- ### 间距规范 - **内容区块间距**:24px - **组件内部间距**:16px - **文本行高**:1.5 - **图标尺寸**:16px / 20px / 24px ### 阴影效果 - **浅阴影**:`0 2px 4px rgba(0,0,0, 0.05)` - **中阴影**:`0 4px 8px rgba(0,0,0, 0.1)` - **深阴影**:`0 8px 16px rgba(0,0,0, 0.15)` ### 圆角规范 - **大圆角**:8px - **中圆角**:4px - **小圆角**:2px APP的效果也还可以
-
Pytorch学习笔记 训练模型数据集划分 数据集通常会被划分为训练集(Training Set)、验证集(Validation Set)和测试集(Test Set),这样可以有效地训练、优化和评估模型的性能。 1. 训练集(Training Set) 作用:用于模型的学习,即让模型调整参数(权重和偏置)。 占比:一般占 60%-80% 的总数据。 细节:模型在这个数据集上不断计算损失 → 反向传播 → 更新参数,以最小化误差。 2. 验证集(Validation Set) 作用:在训练过程中监测模型的表现,用于调整超参数(如学习率、层数、神经元数量等),防止过拟合。 占比:一般占 10%-20% 的总数据。 细节: 训练过程中不会对验证集进行梯度更新,仅用于计算指标(如准确率、损失)。 用于超参数调优,选择最优模型配置。 3. 测试集(Test Set) 作用:在模型完全训练好后,用于最终评估模型的泛化能力。 占比:一般占 10%-20% 的总数据。 细节: 不能用于训练,也不能用于超参数调优,完全独立。 反映模型对未见过的数据的表现,确保模型不会仅仅记住训练数据(过拟合)。 为什么要区分验证集和测试集? 很多人会问:“为什么不直接用测试集来调优超参数?” 原因: 如果我们用测试集来调整超参数,模型就会对测试集产生信息泄露,测试集就不再是真正的未知数据,评估结果会有偏差。 验证集的作用是提供反馈,而测试集的作用是提供最终评分。 数据集划分方法 1. 直接划分 from sklearn.model_selection import train_test_split # 生成示例数据 X = [[i] for i in range(1000)] # 1000 个样本 y = [i % 2 for i in range(1000)] # 二分类标签 # 先划分为训练集 + 剩余集(80% 训练,20% 剩余) X_train, X_rem, y_train, y_rem = train_test_split(X, y, test_size=0.2, random_state=42) # 再划分验证集和测试集(各 10%) X_val, X_test, y_val, y_test = train_test_split(X_rem, y_rem, test_size=0.5, random_state=42) print(f"训练集大小: {len(X_train)}, 验证集大小: {len(X_val)}, 测试集大小: {len(X_test)}") 输出: 训练集大小: 800, 验证集大小: 100, 测试集大小: 100 2. K 折交叉验证(适用于小数据集) 如果数据集较小,可以使用 K 折交叉验证(K-Fold Cross Validation): from sklearn.model_selection import KFold import numpy as np X = np.array(range(100)) kf = KFold(n_splits=5, shuffle=True, random_state=42) # 5 折交叉验证 for train_index, val_index in kf.split(X): print(f"训练集: {train_index}, 验证集: {val_index}") 总结 数据集 作用 是否参与训练 用于超参数调优 何时使用 训练集 训练模型 ✅ ❌ 训练时 验证集 调整超参数,监测过拟合 ❌ ✅ 训练过程中 测试集 评估最终性能 ❌ ❌ 训练结束后 🚀 最佳实践: ✅ 80%-10%-10% 划分(训练-验证-测试) ✅ K 折交叉验证(当数据较少时) 神经网络模型训练的原理 神经网络模型训练的本质是一个 优化过程,核心目标是 最小化损失函数(Loss Function),使得模型对训练数据的预测尽可能准确。训练过程主要包括 前向传播(Forward Propagation)、损失计算(Loss Calculation)、反向传播(Backward Propagation)、参数更新(Parameter Update) 四个关键步骤。 1. 前向传播(Forward Propagation) 计算从输入到输出的结果 输入数据 ( X ) 经过 加权求和 和 激活函数 处理,得到 预测值 ( Y_{\text{pred}} )。 数学公式: [ Z = W \cdot X + b ] [ Y_{\text{pred}} = \sigma(Z) ] 其中: ( W ) 是 权重(Weights) ( b ) 是 偏置(Bias) ( \sigma(Z) ) 是 激活函数(如 ReLU、Sigmoid) 2. 计算损失函数(Loss Calculation) 衡量模型的预测值与真实值之间的差距 损失函数(Loss Function) 用来量化误差,常见损失函数: 回归任务(预测连续值):使用 均方误差(MSE) [ L = \frac{1}{N} \sum (Y_{\text{true}} - Y_{\text{pred}})^2 ] 分类任务(预测类别):使用 交叉熵损失(CrossEntropy) [ L = -\sum Y_{\text{true}} \log(Y_{\text{pred}}) ] 3. 反向传播(Backward Propagation) 计算梯度,调整参数 通过 链式求导法则(Chain Rule) 计算每个参数对损失函数的贡献: [ \frac{\partial L}{\partial W} ] 反向传播的本质是 梯度下降(Gradient Descent): [ W = W - \alpha \cdot \frac{\partial L}{\partial W} ] 其中: ( \alpha ) 是 学习率(Learning Rate) ( \frac{\partial L}{\partial W} ) 是 梯度(Gradient) 4. 参数更新(Parameter Update) 使用优化算法(如 SGD、Adam)调整权重,使损失减少: 随机梯度下降(SGD): [ W = W - \alpha \cdot \frac{\partial L}{\partial W} ] Adam(自适应学习率优化) 计算梯度的指数加权平均 适用于 非平稳数据和稀疏梯度 完整示例:用 PyTorch 训练神经网络 import torch import torch.nn as nn import torch.optim as optim # 1. 准备数据 X = torch.tensor([[1.0], [2.0], [3.0], [4.0]]) # 输入 Y = torch.tensor([[2.0], [4.0], [6.0], [8.0]]) # 真实值 # 2. 构建模型 class LinearRegressionModel(nn.Module): def __init__(self): super().__init__() self.linear = nn.Linear(1, 1) # 一层线性回归模型(y = Wx + b) def forward(self, x): return self.linear(x) model = LinearRegressionModel() # 3. 选择损失函数和优化器 loss_fn = nn.MSELoss() # 均方误差 optimizer = optim.SGD(model.parameters(), lr=0.01) # 4. 训练模型 for epoch in range(100): Y_pred = model(X) # 前向传播 loss = loss_fn(Y_pred, Y) # 计算损失 optimizer.zero_grad() # 清除梯度 loss.backward() # 反向传播 optimizer.step() # 参数更新 if (epoch + 1) % 10 == 0: print(f'Epoch {epoch+1}, Loss: {loss.item():.4f}') # 5. 预测新数据 new_X = torch.tensor([[5.0]]) predicted_Y = model(new_X).item() print(f"预测 5 对应的值: {predicted_Y:.2f}") 总结 步骤 说明 前向传播 计算从输入到输出的预测值 计算损失 计算预测值与真实值的误差 反向传播 计算梯度,优化参数 参数更新 使用梯度下降调整权重 在 PyTorch 中,梯度下降(Gradient Descent)是优化模型参数的核心方法之一。PyTorch 提供了 torch.optim 模块,其中包含了多种优化算法,包括最基本的 随机梯度下降(SGD),以及更高级的优化算法(如 Adam、RMSprop 等)。 1. PyTorch 梯度下降的基本流程 梯度下降的核心步骤如下: 前向传播(Forward Propagation) 计算损失函数(Loss)。 反向传播(Backward Propagation) 计算梯度,即对参数求导。 更新参数(Parameter Update) 使用优化器(如 SGD)更新模型参数。 2. PyTorch 实现梯度下降 (1) 使用 torch.optim.SGD import torch # 创建模型参数(需要计算梯度) w = torch.tensor(2.0, requires_grad=True) # 定义损失函数 L = (w-3)² def loss_fn(w): return (w - 3) ** 2 # 定义优化器(学习率 lr=0.1) optimizer = torch.optim.SGD([w], lr=0.1) # 梯度下降迭代 for i in range(10): loss = loss_fn(w) # 计算损失 optimizer.zero_grad() # 清空梯度 loss.backward() # 计算梯度 optimizer.step() # 更新参数 print(f"Step {i+1}: w = {w.item()}, Loss = {loss.item()}") 流程解析 optimizer.zero_grad(): 清空梯度,避免梯度累积。 loss.backward(): 计算损失对 w 的梯度 ∂L/∂w。 optimizer.step(): 使用 SGD 更新参数: [ w = w - \text{lr} \times \frac{\partial L}{\partial w} ] (2) 手动实现梯度下降 如果不使用 torch.optim,可以手动更新参数: w = torch.tensor(2.0, requires_grad=True) lr = 0.1 # 学习率 for i in range(10): loss = loss_fn(w) # 计算损失 loss.backward() # 计算梯度 with torch.no_grad(): # 关闭梯度计算,防止 PyTorch 记录计算图 w -= lr * w.grad # 参数更新 w.grad.zero_() # 清空梯度 print(f"Step {i+1}: w = {w.item()}, Loss = {loss.item()}") 这里手动计算 w -= lr * w.grad,效果等同于 optimizer.step()。 3. PyTorch 支持的优化算法 除了 SGD,PyTorch 还提供了更高级的优化器: Adam (torch.optim.Adam):适用于大多数任务,收敛快。 RMSprop (torch.optim.RMSprop):适用于非平稳目标函数(如强化学习)。 Adagrad (torch.optim.Adagrad):适用于稀疏数据。 示例(使用 Adam): optimizer = torch.optim.Adam([w], lr=0.1) 4. 选择合适的梯度下降算法 优化器 适用场景 主要特点 SGD 经典梯度下降 适用于凸优化,学习率难以调整 SGD + Momentum 加速收敛 可减少振荡,适用于深度网络 Adam 通用 结合了 RMSprop 和 Momentum,适用性强 RMSprop 适用于非平稳目标 适用于强化学习和递归神经网络 Adagrad 适用于稀疏数据 适合 NLP 任务,梯度会逐渐减小 在深度学习任务中,Adam 是默认的首选优化器。 5. 结论 梯度下降是优化模型的核心方法,PyTorch 提供了自动求导和优化器。 使用 torch.optim 可以方便地管理优化算法,如 SGD 和 Adam。 对于深度学习任务,Adam 通常是更好的选择。
-
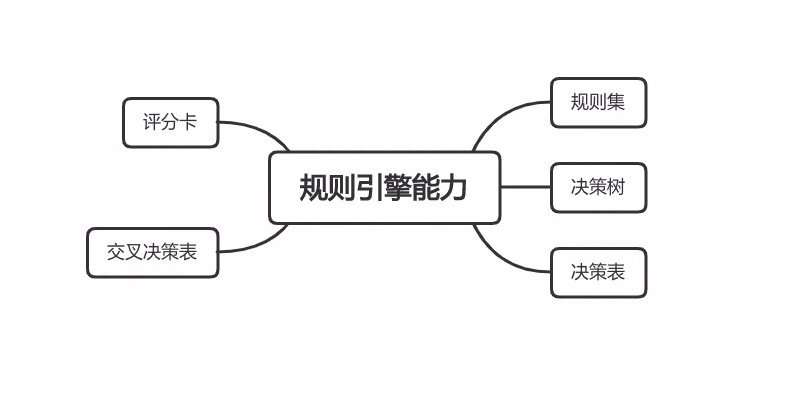
聊一聊规则引擎 规则引擎能力 一、规则集 规则集也叫决策集,是由一组普通规则和循环规则构成的规则集合,是使用频率最高的一种业务规则实现方式。 鲁班提供循环、逻辑(IF/ELSE)、赋值、执行、跳出规则等指令。 经典实例 新用户注册优惠: 如果用户是新注册用户,并且首次购买订单金额超过一定数额,则发送一张10%折扣的优惠券。 购物满减优惠: 如果用户购物车中的商品总价达到一定金额阈值,则自动应用满减优惠。比如,购物车金额大于100元可以享受减免10元的优惠。 特定商品优惠: 如果用户购买特定商品(如促销商品、季节性商品),则提供针对该商品额外的折扣或优惠。 生日优惠券: 在用户生日时发送一张生日优惠券,提供额外的折扣或者赠送特定商品。 用户活跃度奖励: 对于长时间未下单的用户,发送特定额度的优惠券以鼓励再次购买。 地理位置优惠: 针对特定地理位置的用户发送定向的优惠券,以促进当地的销售。 病人风险评估系统规则集示例 考虑以下条件和操作: 年龄: 30岁以下(Young)、30到50岁(Middle-aged)、50岁以上(Elderly)。 生活方式: 锻炼频率(High、Moderate、Low)、饮食习惯(Healthy、Unhealthy)。 慢性病史: 有(Yes)或无(No)。 风险评估等级: 低风险(Low)、中风险(Moderate)、高风险(High)。 规则集示例: FOR(用户集合 ) 用户。年龄 IF 年龄 = Elderly AND (锻炼频率 = Low OR 饮食习惯 = Unhealthy) THEN 风险评估等级 = 高风险 IF 年龄 = Middle-aged AND 慢性病史 = Yes THEN 风险评估等级 = 高风险 IF 年龄 = Young AND 锻炼频率 = High THEN 风险评估等级 = 低风险 IF 年龄 = Elderly AND 锻炼频率 = Moderate THEN 风险评估等级 = 中风险 在这个例子中,规则集根据病人的年龄、生活方式和慢性病史等条件制定了不同的风险评估规则。例如,对于年龄较大且锻炼频率低或饮食不健康的病人,系统会评估其为高风险群体,需要更频繁的检查或干预措施。 这种规则集的应用有助于医疗保健领域更精准地对病人进行风险评估,并根据其个体情况提供相应的医疗建议,从而改善病人的健康状况。 二、决策树 决策树又称为规则树,规则引擎中提供的另外一种构建规则的方式,它以一棵树形结构来表现规则,决策树表现业务规则更为形象,其中每个节点代表一个测试条件,每个分支代表一个测试结果,而每个叶子节点包含一个决策结果。 信用评分系统决策树示例 考虑以下特征和目标: 年龄: 25岁以下(Young)、25到40岁(Middle-aged)、40岁以上(Elderly)。 收入水平: 低收入(Low)、中等收入(Medium)、高收入(High)。 信用历史: 良好(Good)、一般(Fair)、差劣(Poor)。 是否有抵押物: 有(Yes)或无(No)。 信用申请结果: 批准(Approved)或拒绝(Rejected)。 决策树示例: IF 信用历史 = 良好 AND 收入水平 = 高收入 THEN 信用申请结果 = 批准 ELSE IF 信用历史 = 良好 AND 收入水平 = 中等收入 THEN 信用申请结果 = 批准 ELSE IF 信用历史 = 一般 AND 是否有抵押物 = 有 THEN 信用申请结果 = 批准 ELSE IF 信用历史 = 一般 AND 是否有抵押物 = 无 THEN 信用申请结果 = 拒绝 ELSE IF 信用历史 = 差劣 THEN 信用申请结果 = 拒绝 在这个例子中,决策树根据申请者的年龄、收入水平、信用历史和是否有抵押物等特征,自动判断信用申请的结果。例如,如果申请者信用历史良好且收入水平高,那么系统会批准其信用申请;而如果信用历史一般但有抵押物,同样会批准。 这种决策树的应用使得信用评分系统能够自动化、可解释地做出信用决策,提高了效率同时保持了透明度。 三、决策表 决策表是一种以表格形式表现规则的工具,它非常适用于描述处理判断条件较多,各条件又相互组合、有多种决策方案的情况,决策表提供精确而简洁描述复杂逻辑的方式。 视图 使用excel 决策表的应用场景: 业务规则管理: 用于管理和维护大量的业务规则,使得业务规则的管理更加简便和直观。 风险评估: 在金融领域,可以使用决策表来定义风险评估规则,根据客户的不同特征进行信用评级。 产品定价: 在销售领域,可以使用决策表来制定产品定价策略,根据市场条件和产品特性进行灵活的定价。 合规性检查: 在法务和合规性领域,决策表可以用于定义符合法规的业务行为,确保组织的合规性。 推荐系统: 在电商领域,可以使用决策表来定义推荐算法的规则,根据用户的行为和喜好推荐相应的产品 电子商务促销活动管理系统决策表示例 假设我们有以下条件和操作: 用户类型: 普通用户(Regular)和会员用户(Premium)。 购物车金额: 低于100元(Low)和100元及以上(High)。 商品类别: 电子产品(Electronics)、服装(Apparel)、食品(Food)。 促销策略: 折扣(Discount)、满减(Cashback)、免费赠品(Free Gift)。 决策表: 用户类型 购物车金额 商品类别 触发促销策略 操作 普通用户 低金额 电子产品 折扣 应用10%折扣 普通用户 低金额 服装 满减 满200减20 普通用户 高金额 食品 免费赠品 赠送一份免费小吃 会员用户 高金额 电子产品 满减 满500减50 会员用户 低金额 服装 折扣 应用15%折扣 会员用户 高金额 食品 免费赠品 赠送一份免费礼包 在这个例子中,决策表根据用户类型、购物车金额和商品类别等条件定义了不同的促销策略。例如,对于普通用户购买低金额的电子产品,系统会应用10%的折扣;而对于会员用户购买高金额的电子产品,系统则会提供满减优惠。 这样的决策表使得促销活动管理系统能够根据多个条件智能地选择适当的促销策略,提高销售效果和用户满意度。 四、交叉决策表 交叉决策表又叫决策矩阵,是一种特殊类型的决策表。 与普通决策表相比,交叉决策表的条件由纵向和横向两个维度决定,而普通决策表的条件只是由纵向维度决定;但在普通决策表的动作部分可以是三种类型,分别是赋值、输出和执行方式,而在交叉决策表中动作部分就是纵向和横向两个维度交叉后的单元格的值,一般来说,这种交叉后单元格的值都是赋给某个变量或参数,所以交叉决策表的动作基本就一个,那就是赋值。 实际业务场景 假设我们正在开发一个智能家居系统,通过交叉决策表来确定何时触发不同设备的自动化操作。以下是一个简化的实际应用场景: 智能家居系统交叉决策表示例 考虑以下几个条件和设备: 时间段: 白天(Daytime)和夜晚(Nighttime)。 人员在家: 有人在家(Occupied)和无人在家(Unoccupied)。 光照程度: 光线充足(Well-lit)和光线不足(Dimly-lit)。 设备: 灯光(Lights)、温控器(Thermostat)、安全摄像头(Security Camera)。 交叉决策表: 时间段 人员在家 光照程度 触发设备 操作 白天 有人 光线充足 无 保持设备关闭 白天 有人 光线不足 灯光 打开灯光 白天 无人 无 灯光、温控器 打开灯光、调整温度 夜晚 有人 光线充足 无 保持设备关闭 夜晚 有人 光线不足 灯光 打开灯光 夜晚 无人 无 安全摄像头 打开安全摄像头 在这个例子中,交叉决策表综合考虑了时间段、人员在家与否以及光照程度等多个条件。根据这些条件的不同组合,系统可以智能地触发相应的设备操作,使智能家居系统更符合用户的实际需求。例如,在夜晚、有人在家、光线不足的情况下,系统可以自动打开灯光,提高家居的舒适性和安全性。 五、评分卡 评分是对个人或机构的相关信息进行分析之后的一种数值表达,表示此人或此机构由于信用活动的拒付行为所造成损失风险的可能性,评分通常用于对个人或机构的风险管理与评估。 假设我们正在构建一个贷款评分系统,使用评分卡来评估个人信用并决定是否批准其贷款申请。以下是一个简化的实际应用场景: 贷款评分卡示例 考虑以下特征和分数分配: 年龄: 20岁以下(0分)、20到30岁(10分)、30到40岁(20分)、40岁以上(30分)。 收入水平: 低收入(0分)、中等收入(15分)、高收入(30分)。 信用历史: 良好(30分)、一般(15分)、差劣(0分)。 负债比例: 低于30%(20分)、30%到50%(10分)、50%以上(0分)。 工作年限: 不足一年(0分)、1到5年(10分)、5年以上(20分)。 评分卡示例: 总分 = 年龄分 + 收入分 + 信用历史分 + 负债比例分 + 工作年限分 IF 总分 >= 70 THEN 批准贷款 ELSE IF 50 <= 总分 < 70 THEN 需要进一步审查 ELSE 批准贷款 在这个例子中,评分卡通过对申请者的年龄、收入水平、信用历史、负债比例和工作年限等特征进行分数分配,计算出总分。然后,系统通过总分的阈值来决定是否批准贷款。例如,总分大于等于70分的申请者可以直接批准贷款,而总分在50到70之间的申请者需要进一步审查。 这种评分卡的应用使得贷款决策更加客观、可量化,有助于提高贷款审批的效率和一致性。 现有规则引擎在业务端使用评估 业务规则集适合简单IF - THEN逻辑业务和简单循环业务逻辑 决策树适合简单IF - ELSE 带分支的简单业务逻辑使用 复杂多条件场景想使用决策表或者评估卡来创建规则,更符合业务人员的使用习惯 如何使用规则引擎 sequenceDiagram participant BusinessUser as 业务人员 participant BusinessIT as 业务IT人员 participant Implementation as 公司实施人员 BusinessUser ->> BusinessIT: 请求创建具体规则 BusinessIT ->> Implementation: 使用规则引擎配置规则模板和规则包 Implementation ->> BusinessIT: 完成规则配置 BusinessIT ->> BusinessUser: 使用规则模板创建规则 BusinessUser ->> BusinessIT: 提出规则调整需求 BusinessIT ->> BusinessUser: 根据需求调整规则逻辑 BusinessUser ->> BusinessIT: 动态创建和维护规则 在整个Saas系统中,涉及到三个主要角色:业务人员、业务IT人员和公司实施人员。以下是每个角色在规则引擎使用过程中的主要职责: 公司实施人员 规则集、决策树、决策表、交叉决策表、评估卡的规则包创建: 负责使用规则引擎的界面或工具,创建和配置规则集、决策树、决策表、交叉决策表、评估卡的规则包,以便后续的规则模板和规则创建。 业务规则模板的创建: 设计和创建通用的业务规则模板,为业务IT人员提供规则创建的基础结构和规范。 业务IT人员 规则创建: 根据公司实施人员配置好的规则模板和知识包,使用规则引擎的工具创建具体的业务规则,包括规则集、决策树、决策表、交叉决策表、评估卡等。 规则逻辑调整: 负责根据业务需求对已创建的规则进行逻辑调整,确保规则符合业务规则模板和公司实施人员的要求。 规则维护: 定期检查和更新规则,确保规则引擎中的规则集和决策树等结构始终与业务要求保持一致。 业务人员 业务规则调整: 在规则引擎的用户界面中,根据业务需求直接调整已创建的规则,例如修改决策表的条件或调整评估卡的分数等。 规则逻辑优化: 根据业务实际运作的反馈,提出对规则逻辑的优化建议,协助业务IT人员进行调整。 规则动态创建和维护: 在业务变化时,通过规则引擎的界面灵活地创建和维护规则,确保系统能够快速响应业务的变化。 这样的角色划分和职责分配可以使得规则引擎的使用更具灵活性和适应性,不同层次的用户可以专注于其核心职责,共同完成规则的创建和维护。 定制化业务 部分更针对性业务模式由业务团队进行定制页面,如果需要更多定制指令由技术部开发
-
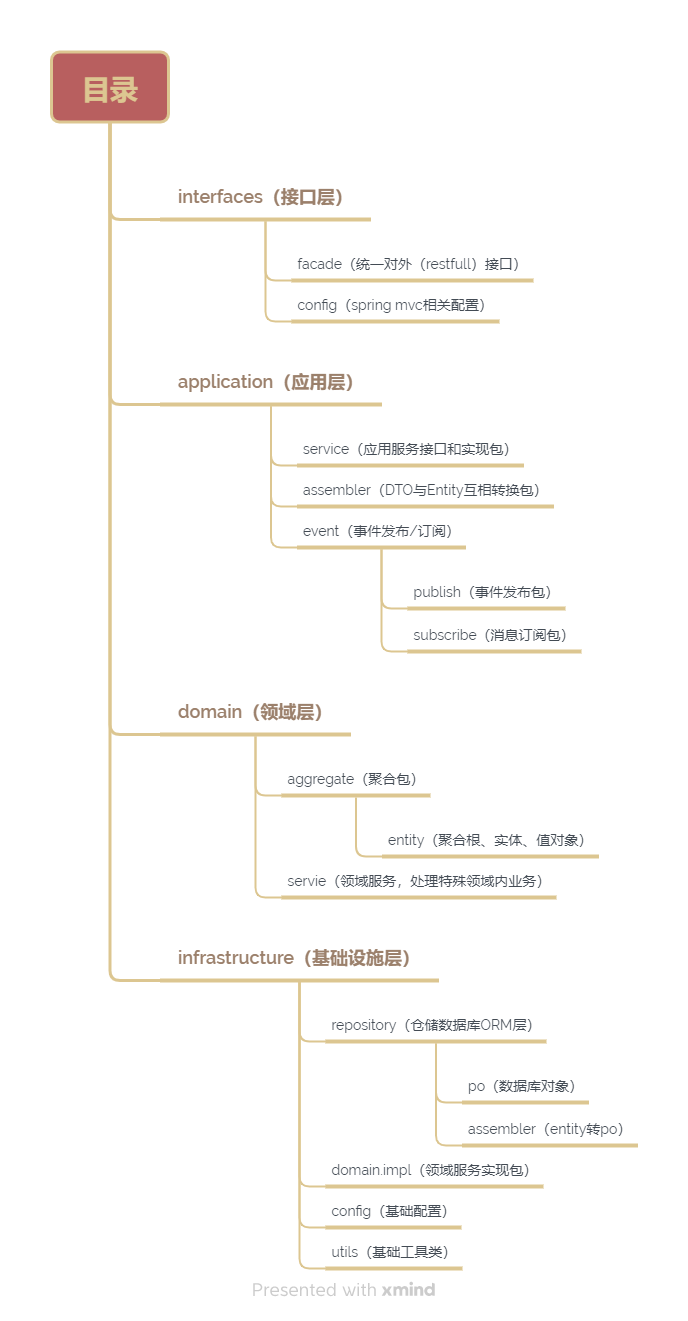
DDD业务服务的目录规划 DDD架构下的工程目录结构划分详解 在领域驱动设计(Domain-Driven Design, DDD)中,合理的工程目录结构对于实现复杂业务逻辑的清晰组织至关重要。本文将详细介绍基于DDD思想的工程目录划分方案,帮助开发团队更好地组织代码,提高系统的可维护性和可扩展性。 DDD工程目录的四层架构 根据思维导图所示,一个标准的DDD架构通常分为四个主要层次: 1. 接口层(interfaces) 接口层是系统与外部交互的门户,负责处理来自外部的请求,并将请求转发到应用层。 facade(统一对外接口):提供RESTful API接口,处理HTTP请求和响应 config(spring mvc相关配置):包含接口层相关的配置,如控制器配置、请求拦截器等 src/main/java/com/company/project/interfaces/ ├── facade/ # 外观模式,统一接口 │ ├── dto/ # 数据传输对象 │ ├── assembler/ # DTO与领域对象转换 │ └── controller/ # 控制器 └── config/ # 接口层配置 2. 应用层(application) 应用层是业务流程的协调者,负责组织领域对象完成特定的应用功能。 service(应用服务接口和实现包):协调领域对象完成业务流程 assembler(DTO与Entity互相转换包):负责应用层与领域层数据模型的相互转换 event(事件发布/订阅) : publish(事件发布包):发布领域事件 subscribe(消息订阅包):订阅并处理领域事件 src/main/java/com/company/project/application/ ├── service/ # 应用服务 │ ├── impl/ # 应用服务实现 │ └── dto/ # 应用服务数据传输对象 ├── assembler/ # DTO与领域对象转换 └── event/ # 事件处理 ├── publish/ # 事件发布 └── subscribe/ # 事件订阅 3. 领域层(domain) 领域层是业务核心,包含业务规则和逻辑。 aggregate(聚合包) :聚合是一组关联的实体和值对象的集合 entity(聚合根、实体、值对象):领域模型核心元素 service(领域服务,处理特殊领域内业务):处理跨实体的业务逻辑 src/main/java/com/company/project/domain/ ├── aggregate/ # 聚合 │ ├── order/ # 订单聚合(示例) │ │ ├── Order.java # 聚合根 │ │ ├── OrderItem.java # 实体 │ │ ├── OrderStatus.java # 值对象 │ │ └── OrderRepository.java # 仓储接口 │ └── user/ # 用户聚合(示例) └── service/ # 领域服务 └── impl/ # 领域服务实现 4. 基础设施层(infrastructure) 基础设施层为其他层提供技术支持。 repository(仓储数据库ORM层) : po(数据库对象):数据库表映射对象 assembler(entity转po):领域对象与数据库对象转换 domain.impl(领域服务实现包):领域服务的具体实现 config(基础配置):系统基础配置 utils(基础工具类):通用工具类 src/main/java/com/company/project/infrastructure/ ├── repository/ # 仓储实现 │ ├── po/ # 持久化对象 │ ├── assembler/ # 领域对象与持久化对象转换 │ ├── mapper/ # MyBatis映射接口 │ └── impl/ # 仓储接口实现 ├── domain/ # 领域层实现 │ └── impl/ # 领域服务实现类 ├── config/ # 基础配置 └── utils/ # 工具类 目录结构的实践建议 按领域划分而非技术功能:在DDD中,首先应该按照业务领域进行划分,而非按照技术功能(如controller、service、dao等) 考虑限界上下文:不同的业务上下文应该有清晰的边界,可以在目录结构中体现 聚合根作为目录划分的基础:每个聚合根可以作为一个子目录,包含相关的实体和值对象 保持领域逻辑的纯净:领域层不应依赖其他层,特别是不应依赖基础设施层 接口与实现分离:定义清晰的接口,并将实现放在适当的包中 示例目录结构(电子商务系统) src/main/java/com/ecommerce/ ├── interfaces/ │ ├── facade/ │ │ ├── order/ # 订单接口 │ │ └── product/ # 产品接口 │ └── config/ # 接口配置 ├── application/ │ ├── service/ │ │ ├── order/ # 订单应用服务 │ │ └── product/ # 产品应用服务 │ ├── assembler/ # DTO转换器 │ └── event/ │ ├── publish/ # 事件发布 │ └── subscribe/ # 事件订阅 ├── domain/ │ ├── aggregate/ │ │ ├── order/ # 订单聚合 │ │ ├── product/ # 产品聚合 │ │ └── user/ # 用户聚合 │ └── service/ # 领域服务 └── infrastructure/ ├── repository/ │ ├── po/ # 持久化对象 │ ├── assembler/ # 对象转换 │ └── impl/ # 仓储实现 ├── domain/ # 领域实现 ├── config/ # 系统配置 └── utils/ # 工具类 结语 DDD在项目中的应用还有待进一步验证,记录一下DDD业务服务的规划。