搜索到
27
篇与
的结果
-
 Java8阅读笔记 懂得什么是行为参数化 http://www.tuicool.com/articles/yIv2Mjy 对比: 通过IntelliJ IDEA 2016.3 来更好使用Java 8的Stream API 归约 使用归约方法的有事和并行化: 相比于前面写的逐步迭代求和,使用reduce的好处在于,这里的迭代被内部迭代抽象掉了,这让内部实现得以选择并行执行reduce操作。而迭代式求和例子要更新共享变量sum,这不是那么容易并行化的。如果你加入了同步,很可能会发现线程竞争抵消了并行本应带来的性能提升! java8 策略模式重构:P192 例子:对输入的内容进行验证或者格式化(比如只包含小写字母或者数字)。 // 此接口实际是一个函数接口 public interface ValidationStrategy { boolean execute(String s); } // 两个实现类 public class IsAllLowerCase implements ValidationStrategy { public boolean execute(String s) { return s.matches("[a-z] +"); } } public class IsNumeric implements ValidationStrategy { public boolean execute(String s) { return s.matches("\\d+""); } } / / 定义一个类去使用 public class Validator{ private final ValidationStrategy strategy; public Validator(ValidationStrategy v){ this.strategy = v; } public boolean validate(String s){ return strategy.execute(s); } } // 实际业务中使用 Validator numericValidateor = new Validator(new IsNumeric()); boolean b1 = numericValidator.validate("aaaa"); Validator lowerCaseValidator = new Validator(new IsAllLowerCase()); boolean b2 = lowerCaseValidator.validate("bbbb"); 使用Lambda表达式: 不需要编写两个实现类直接使用Lambda表达式: Validator numericValidator = new Validator((String s) -> s.matches("[a-z]+")); boolean b1 = numericValidaor.validate("aaaa"); Validator lowerCaseValidator = new Validator((String s) -> s.matches("\\d+")); boolean b2 = lowerCaseValidator.validate("bbbb"); 引入Optional类的意图并非消除每一个null引用。 创建Optional对象 1.声明一个空的Optional Optional<Car> optCar = Optional.empty(); 2.依据一个非空值创建Optional Optional<Car> optCar = Optional.of(car);// 如果car是一个null,这段代码会立即抛出一个NullPointerException,而不是你访问car属性值时才返回一个错误。 3.可接受null的Optional Optional<Car> optCar = Optional.ofNullable(car); 如果car是null,那么得到的Optional对象就是个空对象。 两层Optional嵌套必须使用flatMap 如果你引用第三方库是需要序列化的,使用Optional可能会出错。 如果您返回的的是OptionalInt(基础类型)类型的对象,你就不能将其作为方法引用传递给另一个Optional对象的flatMap方法
Java8阅读笔记 懂得什么是行为参数化 http://www.tuicool.com/articles/yIv2Mjy 对比: 通过IntelliJ IDEA 2016.3 来更好使用Java 8的Stream API 归约 使用归约方法的有事和并行化: 相比于前面写的逐步迭代求和,使用reduce的好处在于,这里的迭代被内部迭代抽象掉了,这让内部实现得以选择并行执行reduce操作。而迭代式求和例子要更新共享变量sum,这不是那么容易并行化的。如果你加入了同步,很可能会发现线程竞争抵消了并行本应带来的性能提升! java8 策略模式重构:P192 例子:对输入的内容进行验证或者格式化(比如只包含小写字母或者数字)。 // 此接口实际是一个函数接口 public interface ValidationStrategy { boolean execute(String s); } // 两个实现类 public class IsAllLowerCase implements ValidationStrategy { public boolean execute(String s) { return s.matches("[a-z] +"); } } public class IsNumeric implements ValidationStrategy { public boolean execute(String s) { return s.matches("\\d+""); } } / / 定义一个类去使用 public class Validator{ private final ValidationStrategy strategy; public Validator(ValidationStrategy v){ this.strategy = v; } public boolean validate(String s){ return strategy.execute(s); } } // 实际业务中使用 Validator numericValidateor = new Validator(new IsNumeric()); boolean b1 = numericValidator.validate("aaaa"); Validator lowerCaseValidator = new Validator(new IsAllLowerCase()); boolean b2 = lowerCaseValidator.validate("bbbb"); 使用Lambda表达式: 不需要编写两个实现类直接使用Lambda表达式: Validator numericValidator = new Validator((String s) -> s.matches("[a-z]+")); boolean b1 = numericValidaor.validate("aaaa"); Validator lowerCaseValidator = new Validator((String s) -> s.matches("\\d+")); boolean b2 = lowerCaseValidator.validate("bbbb"); 引入Optional类的意图并非消除每一个null引用。 创建Optional对象 1.声明一个空的Optional Optional<Car> optCar = Optional.empty(); 2.依据一个非空值创建Optional Optional<Car> optCar = Optional.of(car);// 如果car是一个null,这段代码会立即抛出一个NullPointerException,而不是你访问car属性值时才返回一个错误。 3.可接受null的Optional Optional<Car> optCar = Optional.ofNullable(car); 如果car是null,那么得到的Optional对象就是个空对象。 两层Optional嵌套必须使用flatMap 如果你引用第三方库是需要序列化的,使用Optional可能会出错。 如果您返回的的是OptionalInt(基础类型)类型的对象,你就不能将其作为方法引用传递给另一个Optional对象的flatMap方法 -
使用Metrics指标度量工具监控Java应用程序性能(Gauges, Counters, Histograms, Meters和 Timers实例) Metrics是一个给JAVA服务的各项指标提供度量工具的包,在JAVA代码中嵌入Metrics代码,可以方便的对业务代码的各个指标进行监控,同时,Metrics能够很好的跟Ganlia、Graphite结合,方便的提供图形化接口。基本使用方式直接将core包(目前稳定版本3.0.1)导入pom文件即可,配置如下: <dependency> <groupId>com.codahale.metrics</groupId> <artifactId>metrics-core</artifactId> <version>3.0.1</version> </dependency> core包主要提供如下核心功能: Metrics Registries类似一个metrics容器,维护一个Map,可以是一个服务一个实例。 支持五种metric类型:Gauges、Counters、Meters、Histograms和Timers。 可以将metrics值通过JMX、Console,CSV文件和SLF4J loggers发布出来。 五种Metrics类型: Gauges Gauges是一个最简单的计量,一般用来统计瞬时状态的数据信息,比如系统中处于pending状态的job。测试代码 package com.netease.test.metrics; import com.codahale.metrics.ConsoleReporter; import com.codahale.metrics.Gauge; import com.codahale.metrics.JmxReporter; import com.codahale.metrics.MetricRegistry; import java.util.Queue; import java.util.concurrent.LinkedBlockingDeque; import java.util.concurrent.TimeUnit; /** * User: hzwangxx * Date: 14-2-17 * Time: 14:47 * 测试Gauges,实时统计pending状态的job个数 */ public class TestGauges { /** * 实例化一个registry,最核心的一个模块,相当于一个应用程序的metrics系统的容器,维护一个Map */ private static final MetricRegistry metrics = new MetricRegistry(); private static Queue<String> queue = new LinkedBlockingDeque<String>(); /** * 在控制台上打印输出 */ private static ConsoleReporter reporter = ConsoleReporter.forRegistry(metrics).build(); public static void main(String[] args) throws InterruptedException { reporter.start(3, TimeUnit.SECONDS); //实例化一个Gauge Gauge<Integer> gauge = new Gauge<Integer>() { @Override public Integer getValue() { return queue.size(); } }; //注册到容器中 metrics.register(MetricRegistry.name(TestGauges.class, "pending-job", "size"), gauge); //测试JMX JmxReporter jmxReporter = JmxReporter.forRegistry(metrics).build(); jmxReporter.start(); //模拟数据 for (int i=0; i<20; i++){ queue.add("a"); Thread.sleep(1000); } } } /* console output: 14-2-17 15:29:35 =============================================================== -- Gauges ---------------------------------------------------------------------- com.netease.test.metrics.TestGauges.pending-job.size value = 4 14-2-17 15:29:38 =============================================================== -- Gauges ---------------------------------------------------------------------- com.netease.test.metrics.TestGauges.pending-job.size value = 6 14-2-17 15:29:41 =============================================================== -- Gauges ---------------------------------------------------------------------- com.netease.test.metrics.TestGauges.pending-job.size value = 9 */ 通过以上步骤将会向MetricsRegistry容器中注册一个名字为com.netease.test.metrics .TestGauges.pending-job.size的metrics,实时获取队列长度的指标。另外,Core包种还扩展了几种特定的Gauge: JMX Gauges—提供给第三方库只通过JMX将指标暴露出来。 Ratio Gauges—简单地通过创建一个gauge计算两个数的比值。 Cached Gauges—对某些计量指标提供缓存 Derivative Gauges—提供Gauge的值是基于其他Gauge值的接口。 Counter Counter是Gauge的一个特例,维护一个计数器,可以通过inc()和dec()方法对计数器做修改。使用步骤与Gauge基本类似,在MetricRegistry中提供了静态方法可以直接实例化一个Counter。 package com.netease.test.metrics; import com.codahale.metrics.ConsoleReporter; import com.codahale.metrics.Counter; import com.codahale.metrics.MetricRegistry; import java.util.LinkedList; import java.util.Queue; import java.util.concurrent.TimeUnit; import static com.codahale.metrics.MetricRegistry.*; /** * User: hzwangxx * Date: 14-2-14 * Time: 14:02 * 测试Counter */ public class TestCounter { /** * 实例化一个registry,最核心的一个模块,相当于一个应用程序的metrics系统的容器,维护一个Map */ private static final MetricRegistry metrics = new MetricRegistry(); /** * 在控制台上打印输出 */ private static ConsoleReporter reporter = ConsoleReporter.forRegistry(metrics).build(); /** * 实例化一个counter,同样可以通过如下方式进行实例化再注册进去 * pendingJobs = new Counter(); * metrics.register(MetricRegistry.name(TestCounter.class, "pending-jobs"), pendingJobs); */ private static Counter pendingJobs = metrics.counter(name(TestCounter.class, "pedding-jobs")); // private static Counter pendingJobs = metrics.counter(MetricRegistry.name(TestCounter.class, "pedding-jobs")); private static Queue<String> queue = new LinkedList<String>(); public static void add(String str) { pendingJobs.inc(); queue.offer(str); } public String take() { pendingJobs.dec(); return queue.poll(); } public static void main(String[]args) throws InterruptedException { reporter.start(3, TimeUnit.SECONDS); while(true){ add("1"); Thread.sleep(1000); } } } /* console output: 14-2-17 17:52:34 =============================================================== -- Counters -------------------------------------------------------------------- com.netease.test.metrics.TestCounter.pedding-jobs count = 4 14-2-17 17:52:37 =============================================================== -- Counters -------------------------------------------------------------------- com.netease.test.metrics.TestCounter.pedding-jobs count = 6 14-2-17 17:52:40 =============================================================== -- Counters -------------------------------------------------------------------- com.netease.test.metrics.TestCounter.pedding-jobs count = 9 */ 3. Meters Meters用来度量某个时间段的平均处理次数(request per second),每1、5、15分钟的TPS。比如一个service的请求数,通过metrics.meter()实例化一个Meter之后,然后通过meter.mark()方法就能将本次请求记录下来。统计结果有总的请求数,平均每秒的请求数,以及最近的1、5、15分钟的平均TPS。 package com.netease.test.metrics; import com.codahale.metrics.ConsoleReporter; import com.codahale.metrics.Meter; import com.codahale.metrics.MetricRegistry; import java.util.concurrent.TimeUnit; import static com.codahale.metrics.MetricRegistry.*; /** * User: hzwangxx * Date: 14-2-17 * Time: 18:34 * 测试Meters */ public class TestMeters { /** * 实例化一个registry,最核心的一个模块,相当于一个应用程序的metrics系统的容器,维护一个Map */ private static final MetricRegistry metrics = new MetricRegistry(); /** * 在控制台上打印输出 */ private static ConsoleReporter reporter = ConsoleReporter.forRegistry(metrics).build(); /** * 实例化一个Meter */ private static final Meter requests = metrics.meter(name(TestMeters.class, "request")); public static void handleRequest() { requests.mark(); } public static void main(String[] args) throws InterruptedException { reporter.start(3, TimeUnit.SECONDS); while(true){ handleRequest(); Thread.sleep(100); } } } /* 14-2-17 18:43:08 =============================================================== -- Meters ---------------------------------------------------------------------- com.netease.test.metrics.TestMeters.request count = 30 mean rate = 9.95 events/second 1-minute rate = 0.00 events/second 5-minute rate = 0.00 events/second 15-minute rate = 0.00 events/second 14-2-17 18:43:11 =============================================================== -- Meters ---------------------------------------------------------------------- com.netease.test.metrics.TestMeters.request count = 60 mean rate = 9.99 events/second 1-minute rate = 10.00 events/second 5-minute rate = 10.00 events/second 15-minute rate = 10.00 events/second 14-2-17 18:43:14 =============================================================== -- Meters ---------------------------------------------------------------------- com.netease.test.metrics.TestMeters.request count = 90 mean rate = 9.99 events/second 1-minute rate = 10.00 events/second 5-minute rate = 10.00 events/second 15-minute rate = 10.00 events/second */ Histograms Histograms主要使用来统计数据的分布情况,最大值、最小值、平均值、中位数,百分比(75%、90%、95%、98%、99%和99.9%)。例如,需要统计某个页面的请求响应时间分布情况,可以使用该种类型的Metrics进行统计。具体的样例代码如下: package com.netease.test.metrics; import com.codahale.metrics.ConsoleReporter; import com.codahale.metrics.Histogram; import com.codahale.metrics.MetricRegistry; import java.util.Random; import java.util.concurrent.TimeUnit; import static com.codahale.metrics.MetricRegistry.name; /** * User: hzwangxx * Date: 14-2-17 * Time: 18:34 * 测试Histograms */ public class TestHistograms { /** * 实例化一个registry,最核心的一个模块,相当于一个应用程序的metrics系统的容器,维护一个Map */ private static final MetricRegistry metrics = new MetricRegistry(); /** * 在控制台上打印输出 */ private static ConsoleReporter reporter = ConsoleReporter.forRegistry(metrics).build(); /** * 实例化一个Histograms */ private static final Histogram randomNums = metrics.histogram(name(TestHistograms.class, "random")); public static void handleRequest(double random) { randomNums.update((int) (random*100)); } public static void main(String[] args) throws InterruptedException { reporter.start(3, TimeUnit.SECONDS); Random rand = new Random(); while(true){ handleRequest(rand.nextDouble()); Thread.sleep(100); } } } /* 14-2-17 19:39:11 =============================================================== -- Histograms ------------------------------------------------------------------ com.netease.test.metrics.TestHistograms.random count = 30 min = 1 max = 97 mean = 45.93 stddev = 29.12 median = 39.50 75% <= 71.00 95% <= 95.90 98% <= 97.00 99% <= 97.00 99.9% <= 97.00 14-2-17 19:39:14 =============================================================== -- Histograms ------------------------------------------------------------------ com.netease.test.metrics.TestHistograms.random count = 60 min = 0 max = 97 mean = 41.17 stddev = 28.60 median = 34.50 75% <= 69.75 95% <= 92.90 98% <= 96.56 99% <= 97.00 99.9% <= 97.00 14-2-17 19:39:17 =============================================================== -- Histograms ------------------------------------------------------------------ com.netease.test.metrics.TestHistograms.random count = 90 min = 0 max = 97 mean = 44.67 stddev = 28.47 median = 43.00 75% <= 71.00 95% <= 91.90 98% <= 96.18 99% <= 97.00 99.9% <= 97.00 */ 5. Timers Timers主要是用来统计某一块代码段的执行时间以及其分布情况,具体是基于Histograms和Meters来实现的。样例代码如下: package com.netease.test.metrics; import com.codahale.metrics.ConsoleReporter; import com.codahale.metrics.MetricRegistry; import com.codahale.metrics.Timer; import java.util.Random; import java.util.concurrent.TimeUnit; import static com.codahale.metrics.MetricRegistry.name; /** * User: hzwangxx * Date: 14-2-17 * Time: 18:34 * 测试Timers */ public class TestTimers { /** * 实例化一个registry,最核心的一个模块,相当于一个应用程序的metrics系统的容器,维护一个Map */ private static final MetricRegistry metrics = new MetricRegistry(); /** * 在控制台上打印输出 */ private static ConsoleReporter reporter = ConsoleReporter.forRegistry(metrics).build(); /** * 实例化一个Meter */ // private static final Timer requests = metrics.timer(name(TestTimers.class, "request")); private static final Timer requests = metrics.timer(name(TestTimers.class, "request")); public static void handleRequest(int sleep) { Timer.Context context = requests.time(); try { //some operator Thread.sleep(sleep); } catch (InterruptedException e) { e.printStackTrace(); } finally { context.stop(); } } public static void main(String[] args) throws InterruptedException { reporter.start(3, TimeUnit.SECONDS); Random random = new Random(); while(true){ handleRequest(random.nextInt(1000)); } } } /* 14-2-18 9:31:54 ================================================================ -- Timers ---------------------------------------------------------------------- com.netease.test.metrics.TestTimers.request count = 4 mean rate = 1.33 calls/second 1-minute rate = 0.00 calls/second 5-minute rate = 0.00 calls/second 15-minute rate = 0.00 calls/second min = 483.07 milliseconds max = 901.92 milliseconds mean = 612.64 milliseconds stddev = 196.32 milliseconds median = 532.79 milliseconds 75% <= 818.31 milliseconds 95% <= 901.92 milliseconds 98% <= 901.92 milliseconds 99% <= 901.92 milliseconds 99.9% <= 901.92 milliseconds 14-2-18 9:31:57 ================================================================ -- Timers ---------------------------------------------------------------------- com.netease.test.metrics.TestTimers.request count = 8 mean rate = 1.33 calls/second 1-minute rate = 1.40 calls/second 5-minute rate = 1.40 calls/second 15-minute rate = 1.40 calls/second min = 41.07 milliseconds max = 968.19 milliseconds mean = 639.50 milliseconds stddev = 306.12 milliseconds median = 692.77 milliseconds 75% <= 885.96 milliseconds 95% <= 968.19 milliseconds 98% <= 968.19 milliseconds 9
-
一致性算法--Raft 一致性算法--Raft 分布式一致性算法--Raft 前面一篇文章讲了Paxos协议,这篇文章讲它的姊妹篇Raft协议,相对于Paxos协议,Raft协议更为简单,也更容易工程实现。有关Raft协议和工程实现可以参考这个链接https://raft.github.io/,里面包含了大量的论文、视频以及动画演示,非常有助于理解协议。 概念与术语 leader:领导者,为客户提供服务(生成写日志)的节点,任何时候raft系统中只能有一个leader。 follower:跟随者,被动接受请求的节点,不会发送任何请求,只会响应来自leader或者candidate的请求。如果接受到客户请求,会转发给leader。 candidate:候选人,选举过程中产生,follower在超时时间内没有收到leader的心跳或者日志,则切换到candidate状态,进入选举流程。 termId:任期号,时间被划分成一个个任期,每次选举后都会产生一个新的termId,一个任期内只有一个leader。termId相当于paxos的proposalId。 RequestVote:请求投票,candidate在选举过程中发起,收到quorum(多数派)响应后,成为leader。 AppendEntries:附加日志,leader发送日志和心跳的机制。 election timeout:选举超时,如果follower在一段时间内没有收到任何消息(追加日志或者心跳),就是选举超时。 Raft协议主要包括三部分,leader选举,日志复制和成员变更。 Raft协议的原则和特点 a. 系统中有一个leader,所有的请求都交由leader处理,leader发起同步请求,当多数派响应后才返回客户端。 b. leader从来不修改自身的日志,只做追加操作。 c. 日志只从leader流向follower,leader中包含了所有已经提交的日志。 d. 如果日志在某个term中达成了多数派,则以后的任期中日志一定会存在。 e. 如果某个节点在某个(term, index)应用了日志,则在相同的位置,其它节点一定会应用相同的日志。 f. 不依赖各个节点物理时序保证一致性,通过逻辑递增的term - id和log - id保证。 e. 可用性:只要有大多数机器可运行并可相互通信,就可以保证可用,比如5节点的系统可以容忍2节点失效。 f. 容易理解:相对于Paxos协议实现逻辑清晰容易理解,并且有很多工程实现,而Paxos则难以理解,也没有工程实现。 g. 主要实现包括3部分:leader选举,日志复制,复制快照和成员变更;日志类型包括:选举投票,追加日志(心跳),复制快照。 leader选举流程 关键词:随机超时,FIFO 服务器启动时初始状态都是follower,如果在超时时间内没有收到leader发送的心跳包,则进入candidate状态进行选举,服务器启动时和leader挂掉时处理一样。为了避免选票瓜分的情况,比如5个节点ABCDE,leader A挂掉后,还剩4个节点,raft协议约定,每个服务器在一个term只能投一张票,假设B,D分别有最新的日志,且同时发起选举投票,则可能出现B和D分别得到2张票的情况,如果这样都得不到大多数确认,无法选出leader。为了避免这种情况发生,raft利用随机超时机制避免选票瓜分情况。选举超时时间从一个固定的区间随机选择,由于每个服务器的超时时间不同,则leader挂掉后,超时时间最短且拥有最多日志的follower最先开始选主,并成为leader。一旦candidate成为leader,就会向其他服务器发送心跳包阻止新一轮的选举开始。 发送日志信息:(term, candidateId, lastLogTerm, lastLogIndex) candidate流程: 在超时时间内没有收到leader的日志(包括心跳)。 将状态切换为candidate,自增currentTerm,设置超时时间。 向所有节点广播选举请求,等待响应,可能会有以下三种情况: (1). 如果收到多数派回应,则成为leader。 (2). 如果收到leader的心跳,且leader的term >= currentTerm,则自己切换为follower状态,否则,保持Candidate身份。 (3). 如果在超时时间内没有达成多数派,也没有收到leader心跳,则很可能选票被瓜分,则会自增currentTerm,进行新一轮的选举。 follower流程: 如果term < currentTerm,说明有更新的term,返回给candidate。 如果还没有投票,或者candidateId的日志(lastLogTerm, lastLogIndex)和本地日志一样或更新,则投票给它。 注意:一个term周期内,每个节点最多只能投一张票,按照先来先到原则。 日志复制流程 关键词:日志连续一致性,多数派,leader日志不变更 leader向follower发送日志时,会顺带邻近的前一条日志,follower接收日志时,会在相同任期号和索引位置找前一条日志,如果存在且匹配,则接收日志;否则拒绝,leader会减少日志索引位置并进行重试,直到某个位置与follower达成一致。然后follower删除索引后的所有日志,并追加leader发送的日志,一旦日志追加成功,则follower和leader的所有日志就保持一致。只有在多数派的follower都响应接受到日志后,表示事务可以提交,才能返回客户端提交成功。 发送日志信息:(term, leaderId, prevLogIndex, prevLogTerm, leaderCommitIndex) leader流程: 接收到client请求,本地持久化日志。 将日志发往各个节点。 如果达成多数派,再commit,返回给client。 备注: (1). 如果传递给follower的lastLogIndex >= nextIndex,则从nextIndex继续传递。 如果返回成功,则更新follower对应的nextIndex和matchIndex。 如果失败,则表示follower还差更多的日志,则递减nextIndex,重试。 (2). 如果存在N > commitIndex,且多数派matchIndex[i] >= N,且log[N].term == currentTerm,设置commitIndex = N。 follower处理流程: 比较term号和自身的currentTerm,如果term < currentTerm,则返回false。 如果(prevLogIndex, prevLogTerm)不存在,说明还差日志,返回false。 如果(prevLogIndex, prevLogTerm)与已有的日志冲突,则以leader为准,删除自身的日志。 将leader传过来的日志追加到末尾。 如果leaderCommitIndex > commitIndex,说明是新的提交位点,回放日志,设置commitIndex = min(leaderCommitIndex, index of last new entry)。 备注: 默认情况下,如果日志不匹配,会按logIndex逐条往前推进,直到找到match的位置,有一个简单的思路是,每次往前推进一个term,这样可以减少了网络交互,尽快早点match的位置,代价是可能传递了一些多余的日志。 快照流程 避免日志占满磁盘空间,需要定期对日志进行清理,在清理前需要做快照,这样新加入的节点可以通过快照 + 日志恢复。 快照属性: 最后一个已经提交的日志(termId,logIndex)。 新的快照生成后,可以删除之前的日志和以前的快照。 删日志不能太快,否则,crash后的机器,本来可以通过日志恢复,如果日志不存在,需要通过快照恢复,比较慢。 leader发送快照流程 传递参数(leaderTermId, lastIndex, lastTerm, offset, data[], done_flag) 如果发现日志落后太远(超过阀值),则触发发送快照流程。 备注: 快照不能太频繁,否则会导致磁盘IO压力较大;但也需要定期做,清理非必要的日志,缓解日志的空间压力,另外可以提高follower追赶的速度。 follower接收快照流程 如果leaderTermId < currentTerm,则返回。 如果是第一个块,创建快照。 在指定的偏移,将数据写入快照。 如果不是最后一块,等待更多的块。 接收完毕后,丢掉以前旧的快照。 删除掉不需要的日志。 集群配置变更 C(old):旧配置 C(new):新配置 C(old - new):过渡配置,需要同时在old和new中达成多数派才行 原则: 配置变更过程中,不会导致出现两个leader。 二阶段方案: 引入过渡阶段C(old - new) 约定: 任何一个follower在收到新的配置后,就采用新的配置确定多数派。 变更流程: leader收到从C(old)切换到C(new)配置的请求。 创建配置日志C(old - new),这条日志需要在C(old)和C(new)中同时达成多数派。 任何一个follower收到配置后,采用的C(old - new)来确定日志是否达成多数派(即使C(old - new)这条日志还没达成多数派)。 备注: 1,2,3阶段只有可能C(old)节点成为leader,因为C(old - new)没有可能成为多数派。 4. C(old - new)日志commit(达成多数派),则无论是C(old)还是C(new)都无法单独达成多数派,即不会存在两个leader。 5. 创建配置配置日志C(new),广播到所有节点。 6. 同样的,任何一个follower收到配置后,采用的C(new)来确定日志是否达成多数派。 备注: 在4,5,6阶段,只有可能含有C(old - new)配置的节点成为leader。 7. C(new)配置日志commit后,则C(old - new)无法再达成多数派。 8. 对于不在C(new)配置的节点,就可以退出了,变更完成。 备注: 在7,8阶段,只有可能含有C(new)配置成为leader。 所以整个过程中永远只会有一个leader。对于leader不在C(new)配置的情况,需要在C(new)日志提交后,自动关闭。 除了上述的两阶段方案,后续Raft作者又提出了一个相对简单的一阶段方案,每次只添加或者删除一个节点,这样设计不用引入过渡状态,这里不再赘述,有兴趣的同学可以去看他的毕业论文,我会附在后面的参考文档里面。 Q&A 1. Raft协议中是否存在“活锁”,如何解决? 活锁是相对死锁而言,所谓死锁,就是两个或多个线程相互锁等待,导致都无法推进的情况,而活锁则是多个工作线程(节点)都在运转,但是整体系统的状态无法推进,比如basic - paxos中某些情况下投票总是没有办法达成多数派。在Raft中,由于只要一阶段提交,选主过程中,可能出现多个节点同时发起选主的情况,这样导致选票瓜分,无法选出主,在下一轮选举中依旧如此,导致系统状态无法往前推进。Raft通过随机超时解决这个“活锁”问题。 2. Raft系统对于各个节点的物理时钟强一致有要求吗? Raft协议对物理时钟一致性没有要求,不需要通过原子钟NTP来校准时间,但是对于超时时间的设置有要求,具体规则如下: broadcastTime ≪ electionTimeout ≪ MTBF(Mean Time Between Failure) 首先,广播时间要远小于选举超时时间,leader通过广播不间断给follower发送心跳,如果这个时间比超时时间短,就会导致follower误以为leader挂了,触发选主;然后是超时时间要远小于机器的平均故障时间,如果MTBF比超时时间还短,则永远会发生选主问题,而在选主完成之前,无法对外正常提供服务,因此需要保证。一般broadcastTime可以认为是一个网络RTT,同城1ms以内,异地100ms以内,如果是跨国家,可能需要几百ms;而机器平均故障时间至少是以月为单位,因此选举超时时间需要设置1s到5s左右即可。 3. 如何保证leader上拥有了所有日志? 一方面,对于leader不变场景,日志只能从leader流向follower,并且发生冲突时以leader的日志为准;另一方面,对于leader一直有变换的场景,通过选举机制来保证,选举时采用(LogTerm, LogIndex)谁更新的比对方式,并且要得到多数派的认可,说明新leader的日志至少是多数派中最新的,另一方面,提交的日志一定也是达成了多数派,所以推断出leader有所有已提交的日志,不会漏。 4. Raft协议为什么需要日志连续性,日志连续性有有什么优势和劣势? 由Raft协议的选主过程可知,(termId, logId)一定在多数派中最新才可能成为leader,也就是说leader中一定已经包含了所有已经提交的日志。所以leader不需要从其它follower节点获取日志,保证了日志永远只从leader流向follower,简化了逻辑。但缺陷在于,任何一个follower在接受日志前,都需要接受之前的所有日志,并且只有追赶上了,才能有投票权利【否则,复制日志时,不考虑它们是大多数】,如果日志差的比较多,就会导致follower需要较长的时间追赶。任何一个没有追上最新日志的follower,没有投票权利,导致网络比较差的情况下,不容易达成多数派。而Paxos则允许日志有“空洞”,对网络抖动的容忍性更好,但处理“空洞”的逻辑比较复杂。 5. Raft如何保证日志连续性? leader向follower发送日志时,会顺带邻近的前一条日志,follower接受日志时,会在相同任期号和索引位置找前一条日志,如果存在且匹配,则接受日志,否则拒绝接受,leader会减少日志索引位置并进行重试,直到某个位置与follower达成一致。然后follower删除索引后的所有日志,并追加leader发送的日志,一旦日志追加成功,则follower和leader的所有日志就保持一致。而Paxos协议没有日志连续性要求,可以乱序确认。 6. 如果TermId小的先达成多数派,TermId大的怎么办?可能吗? 如果TermId小的达成了多数派,则说明TermId大的节点以前是leader,拥有最多的日志,但是没有达成多数派,因此它的日志可以被覆盖。但该节点会尝试继续投票,新leader发送日志给该节点,如果leader发现返回的termT > currentTerm,且还没有达成多数派,则重新变为follower,促使TermId更大的节点成为leader。但并不保证拥有较大termId的节点一定会成为leader,因为leader是优先判断是否达成多数派,如果已经达成多数派了,则继续为leader。 7. 达成多数派的日志就一定认为是提交的? 不一定,一定是在current_term内产生的日志,并且达成多数派才能认为是提交的,持久化的,不会变的。Raft中,leader保持原始日志的termId不变,任何一条日志,都有termId和logIndex属性。在leader频繁变更的情况下,有可能出现某条日志在某种状态下达成了多数派,但日志最终可能被覆盖掉,比如: (a). S1是leader,termId是2,写了一条日志到S1和S2,(termId,logIndex)为(2, 2) (b). S1 crash,S5利用S3,S4,S5当选leader,自增termId为3,本地写入一条日志,(termId,logIndex)为(3, 2) (c). S5 crash,S1重启后重新当选leader,自增termId为4,将(2, 2)重新复制到多数派,提交前crash (d). S1 crash,S5利用S2,S3,S4当选leader,则将(3, 2)的日志重新复制到多数派,并提交,这样(2, 2)这条日志曾经虽然达成多数派也会被覆盖。 (e). 假设S1在第一个任期内,将(2, 2)达成多数派,则后面S3不会成为leader,也就不会出现覆盖的情况。 参考文档 https://raft.github.io/raft.pdf https://ramcloud.stanford.edu/~ongaro/thesis.pdf https://ramcloud.stanford.edu/~ongaro/userstudy/paxos.pdf
-
一句话概括下spring框架及spring cloud框架主要组件 Spring框架及Spring Cloud框架主要组件概括 Spring是Java领域的主流技术框架集合,包含众多项目: Spring顶级项目: Spring IO platform:用于系统部署,是可集成的现代化应用版本平台,在使用maven dependency引入spring jar包时发挥作用。 Spring Boot:简化产品级Spring应用和服务创建,简化配置文件,用嵌入式web服务器,含开箱即用微服务功能,可与spring cloud联合部署。 Spring Framework:即通常说的spring框架,开源的Java/Java EE全功能栈应用程序框架,其他spring项目如spring boot依赖于此。 Spring Cloud:微服务工具包,提供分布式系统的配置管理、服务发现、断路器、智能路由等开发工具包。 Spring XD:运行时环境(服务器软件,非开发框架),组合spring技术采集和处理大数据。 Spring Data:数据访问及操作工具包,封装多种数据及数据库访问技术。 Spring Batch:批处理框架,具备任务调度、日志记录/跟踪等功能。 Spring Security:为基于Spring的企业应用提供声明式安全访问控制解决方案。 Spring Integration:面向企业应用集成的编程框架,支持多种通信方式。 Spring Social:连接社交服务API的工具包,可连接如Twitter、Facebook等。 Spring AMQP:消息队列操作工具包,主要封装RabbitMQ操作。 Spring HATEOAS:支持实现超文本驱动的REST Web服务的开发库。 Spring Mobile:Spring MVC的扩展,简化手机上Web应用开发。 Spring for Android:Spring框架扩展,简化Android本地应用开发,提供RestTemplate访问Rest服务。 Spring Web Flow:管理Web应用页面流程,将页面跳转流程单独管理并可配置。 Spring LDAP:操作LDAP的Java工具包,基于Spring的JdbcTemplate模式简化LDAP访问。 Spring Session:session管理工具包,可将session保存到redis等进行集群化管理。 Spring Web Services:基于Spring的Web服务框架,提供SOAP服务开发,支持多种方式创建Web服务。 Spring Shell:提供交互式Shell,可用简单Spring编程模型开发命令。 Spring Roo:Spring开发辅助工具,用命令行生成自动化项目。 Spring Scala:为Scala语言编程提供spring框架封装。 Spring BlazeDS Integration:开发RIA工具包,可集成Adobe Flex、BlazeDS、Spring及Java技术创建RIA。 Spring Loaded:实现java程序和web应用热部署的开源工具。 Spring REST Shell:调用Rest服务的命令行工具。 目前Spring主要聚焦于Spring Boot(用于开发微服务)和Spring Cloud相关框架开发,Spring Cloud子项目包括: Spring Cloud Config:配置管理开发工具包,支持将配置放远程服务器,支持本地存储、Git及Subversion。 Spring Cloud Bus:事件、消息总线,在集群中传播状态变化,可与Spring Cloud Config联合实现热部署。 Spring Cloud Netflix:针对多种Netflix组件的开发工具包,含Eureka、Hystrix、Zuul、Archaius等。 Netflix Eureka:云端负载均衡,基于REST服务,用于定位服务,实现负载均衡和故障转移。 Netflix Hystrix:容错管理工具,控制服务和第三方库节点,增强容错能力。 Netflix Zuul:边缘服务工具,提供动态路由、监控等功能。 Netflix Archaius:配置管理API,含系列配置管理API,提供多种功能。 Spring Cloud for Cloud Foundry:通过Oauth2协议绑定服务到CloudFoundry(开源PaaS云平台)。 Spring Cloud Sleuth:日志收集工具包,封装Dapper、Zipkin和HTrace操作。 Spring Cloud Data Flow:大数据操作工具,通过命令行操作数据流。 Spring Cloud Security:安全工具包,为应用添加OAuth2安全控制。 Spring Cloud Consul:封装Consul操作,Consul是服务发现与配置工具,可与Docker容器无缝集成。 Spring Cloud Zookeeper:操作Zookeeper的工具包,用于服务注册和发现。 Spring Cloud Stream:数据流操作开发包,封装与Redis、Rabbit、Kafka等发送接收消息操作。 Spring Cloud CLI:基于Spring Boot CLI,可命令行快速建立云组件。
-
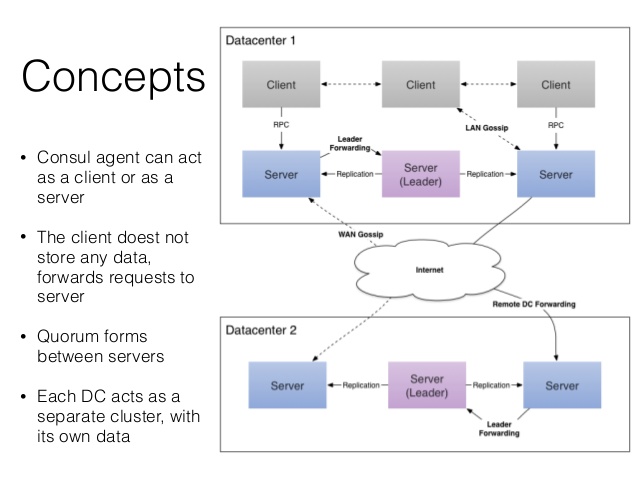
consul 入门 服务管理软件相关知识 1. 概述 一个支持多数据中心下,分布式高可用的服务管理软件,具备服务发现和配置共享功能。以consul为例,consul支持健康检查,允许存储键值对,一致性协议采用Raft算法保证服务高可用,成员管理和消息广播采用GOSSIP协议,支持ACL访问控制。 ACL技术在路由器中广泛采用,是基于包过滤的流控制技术,控制列表以源地址、目的地址及端口号为基本检查元素,规定符合条件的数据包是否允许通过。 gossip是p2p协议,去中心化,模拟人类传播谣言行为,有种子节点,种子节点每秒随机向其他节点发送自己的节点列表及要传播的消息,新加入节点能很快被全网知晓。 服务注册是一个服务将其位置信息在“中心注册节点”注册的过程,一般会注册主机IP地址、端口号,有时还有服务访问认证信息、使用协议、版本号及环境细节信息。 服务发现可让应用或组件发现其运行环境及其他应用或组件的信息,用户配置服务发现工具可分离实际容器与运行配置,常见配置信息有ip、端口号、名称等。当服务存在于多个主机节点上时,传统用静态配置实现服务信息注册,复杂系统中,为避免服务中断,动态的服务注册和发现很重要。 相关开源项目有Zookeeper,Doozer,Etcd等强一致性项目,主要用于服务间协调,也可用于服务注册。 强一致性协议是按照某一顺序串行执行存储对象读写操作,更新存储对象后,后续访问总是读到最新值,常见实现方法有主从同步复制和quorum复制等。 参考链接:http://blog.csdn.net/shlazww/article/details/38736511 2. consul的具体应用场景 docker、coreos 实例的注册与配置共享 vitess集群 SaaS应用的配置共享 与confd服务集成,动态生成nignx与haproxy配置文件 3. 优势 使用Raft算法保证一致性,比poxes算法更直接,zookeeper采用poxes算法。 Raft将过程分为leader election,log replication和commit(safety)三个阶段,每个server有leader,follower,candidate三种状态,正常时只有一个leader,其他为follower,server间通过RPC消息通信,follower不主动发起RPC,leader和candidate(选主时)主动发起。先选一个leader负责管理日志复制,leader接收log entries并复制给其他机器,决定何时将日志应用于状态机,leader可决定新entries位置,数据从leader流向其他机器,leader故障或失联会选举新leader。 参考链接:http://www.jdon.com/artichect/raft.html http://blog.csdn.net/cszhouwei/article/details/38374603 支持多数据中心,内外网服务用不同端口监听,避免单点故障,zookeeper等不支持多数据中心功能。 支持健康检查 提供web界面 支持http协议与dns协议接口 4. 安装(mac os x) 通过工具安装: brew cask install consul brew cask安装方便,参考链接:http://brew.sh/#install 5. 测试 与 运行consul 测试: consul 以服务端形式运行consul: consul agent -server -bootstrap-expect 1 -data-dir /tmp/consul 查看consul服务节点: consul members 将http请求发给consul server: $ curl localhost:8500/v1/catalog/nodes [{"Node":"Armons-MacBook-Air","Address":"10.1.10.38"}] 6. 注册服务 创建文件夹/etc/consul.d ,.d表示里面有许多配置文件。 将服务配置文件写入文件夹内,如: $ echo '{"service": {"name": "web", "tags": ["rails"], "port": 80}}' >/etc/consul.d/web.json 重启consul,并将配置文件的路径给consul: $ consul agent -server -bootstrap-expect 1 -data-dir /tmp/consul -config-dir /etc/consul.d 查询ip和端口: DNS方式: dig @127.0.0.1 -p 8600 web.service.consul SRV - **Http方式**: curl http://localhost:8500/v1/catalog/service/web 更新:通过http api能对service配置文件增删改查,更新完成后,可通过signup命令生效。 7. 组建集群 一个consul agent是独立程序,长时间运行的守护进程,运行在concul集群每个节点上。启动一个consul agent是孤立node,想知道集群其他节点需加入集群。 agent有server与client两种模式,server模式负责一致性工作,保证一致性和可用性(部分失败时),响应RPC,同步数据到其他节点代理;client模式与server通信,转发RPC到服务的代理agent,仅保存少量自身状态,轻量化、无状态。 agent除设置server/client模式、数据路径外,最好设置node的名称和ip。 LAN gossip pool包含同一局域网内所有节点(server与client),基本位于同一个数据中心DC;WAN gossip pool一般仅包含server,跨越多个DC数据中心,通过互联网或广域网通信。Leader服务器负责所有RPC请求查询并响应,其他服务器收到client的RPC请求会转发到leader服务器。 安装vagrant,初始化vagrant环境: sudo vagrant init 启动一个虚拟node节点: vagrant up 查看vm启动状态(包括vm名称): vagrant status 登陆到vm节点: vagrant ssh vm_name bootstrap模式下node可指定自己为leader,无需选举,然后依次启动其他server(非bootstrap模式),最后停止第一个server的bootstrap模式,重新以非bootstrap模式启动,server间自动选举leader。 分别在两个vm上配置consul agent,如: $ vagrant ssh n1 vagrant@n1:~$ consul agent -server -bootstrap-expect 1 \ -data-dir /tmp/consul -node=agent-one -bind=172.20.20.10 $ vagrant ssh n2 vagrant@n2:~$ consul agent -data-dir /tmp/consul -node=agent-two \ -bind=172.20.20.11 此时,应用consul members查询,两个consul node独立无关联。 将client加入到server集群中: vagrant@n1:~$ consul join 172.20.20.11 再用consul members查询,会发现多了一个node节点。 手动加入新节点麻烦,较好方法是将节点配置成自动加入集群: consul agent -atlas-join \ -atlas=ATLAS_USERNAME/infrastructure \ -atlas-token="YOUR_ATLAS_TOKEN" 离开集群: ctrl+c,或者 kill 指定的agent进程,就可以将相关的agent推出集群 让consul运行起来,consul server推荐3~5个,先启动一台server并配置到bootstrap模式,再依次启动其他server(非bootstrap模式),最后停止第一个server的bootstrap模式,重新以非bootstrap模式启动,server间自动选举leader。 参考链接:http://www.bubuko.com/infodetail-800623.html 8. 查询健康状态 应用http接口查询失败的节点: curl http://localhost:8500/v1/health/state/critical 对于失败的节点,应用DNS查询时无法拿到返回结果: dig @127.0.0.1 -p 8600 web.service.consul 9. K/V存储 查询所有K/V: curl -v http://localhost:8500/v1/kv/?recurse 保存键为web/key2, flags 为42, 值为true的记录: curl -X PUT -d 'test' http://localhost:8500/v1/kv/web/key2?flags=42 true 删除记录: curl -X DELETE http://localhost:8500/v1/kv/web/sub?recurse 更新值: curl -X PUT -d 'newval' http://localhost:8500/v1/kv/web/key1?cas=97 true 更新index: curl "http://localhost:8500/v1/kv/web/key2?index=101&wait=5s" 结果:[{"CreateIndex":98,"ModifyIndex":101,"Key":"web/key2","Flags":42,"Value":"dGVzdA=="}] 更详细的consul命令详解:http://m.oschina.net/blog/353392 10. 断电恢复outage recover 当有一台服务器不可用时,处理方法: 对服务器进恢复,然后重新上线 用新服务器,替代旧的consul服务器(这两种方式都需要将服务器ip与原来的ip相同) 添加新的服务器,ip无需与原来相同,步骤:停掉所有的consul服务器,将损坏的服务器ip从raft/peer.json中移除,重启其他服务器,并将新的服务器加入集群。 11. 其他 服务发现是怎么工作呢? 每一个服务发现工具都会提供一套API,使得组件可以用其来设置或搜索数据。正是如此,对于每一个组件,服务发现的地址要么强制编码到程序或容器内部,要么在运行时以参数形式提供。通常来说,发现服务用键值对形式实现,采用标准http协议交互。 服务发现门户的工作方式是:当每一个服务启动上线之后,他们通过发现工具来注册自身信息。它记录了一个相关组件若想使用某服务时的全部必要信息。例如,一个MySQL数据库服务会在这注册它运行的ip和端口,如有必要,登录时的用户名和密码也会留下。 当一个服务的消费者上线时,它能够在预设的终端查询该服务的相关信息。然后它就可以基于查到的信息与其需要的组件进行交互。负载均衡就是一个很好的例子,它可以通过查询服务发现得到各个后端节点承受的流量数,然后根据这个信息来调整配置。 这可将配置信息从容器内拿出。一个好处是可以让组件容器更加灵活,并不受限于特定的配置信息。另一个好处是使得组件与一个新的相关服务实例交互时变得简单,可以由管理工具动态进行调整配置。