搜索到
27
篇与
的结果
-
 记录下从SpringBoot2.7升级到SpringBoot3.2.4问题处理 Dataroom从SpringBoot2.7升级到SpringBoot3.2.4 为了使用让DataRoom引入MCP,整合Spring AI体系,升级SrpingBoot 升级到Jakarta EE Java EE 已更改为 Jakarta EE,Spring Boot 3.x 的所有依赖项 API 也从 Java EE 升级为 Jakarta EE。 简单来说,您需要将所有 javax 的 imports 都替换为 jakarta。具体如下: javax.persistence.* -> jakarta.persistence.* javax.validation.* -> jakarta.validation.* javax.servlet.* -> jakarta.servlet.* javax.annotation.* -> jakarta.annotation.* javax.transaction.* -> jakarta.transaction.* 换mybatis依赖 Invalid value type for attribute ‘factoryBeanObjectType‘: java.lang.String 所以升级 Mybatis-Plus 版本为 3.5.5 版本即可,需要注意下 Maven 的坐标标识 是mybatis-plus-spring-boot3-starter,这点和SpringBoot 2 的依赖坐标mybatis-plus-boot-starter有所区别 第一步:注释spring-boot-starter <!-- <dependency>--> <!-- <groupId>com.baomidou</groupId>--> <!-- <artifactId>mybatis-plus-boot-starter</artifactId>--> <!-- <version>${mybatis.plus.version}</version>--> <!-- </dependency>--> 第二步:引入新的依赖 <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-spring-boot3-starter</artifactId> <version>3.5.5</version> </dependency> 第三步 <dependencyManagement> <dependencies> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis-spring</artifactId> <version>3.0.3</version> </dependency> </dependencies> </dependencyManagement> 动态数据源修改 第一步注释如下代码 <dependency> <groupId>com.baomidou</groupId> <artifactId>dynamic-datasource-spring-boot-starter</artifactId> <version>3.5.0</version> </dependency> 第二步:引入依赖 <dependency> <groupId>com.baomidou</groupId> <artifactId>dynamic-datasource-spring-boot3-starter</artifactId> <version>4.2.0</version> </dependency>
记录下从SpringBoot2.7升级到SpringBoot3.2.4问题处理 Dataroom从SpringBoot2.7升级到SpringBoot3.2.4 为了使用让DataRoom引入MCP,整合Spring AI体系,升级SrpingBoot 升级到Jakarta EE Java EE 已更改为 Jakarta EE,Spring Boot 3.x 的所有依赖项 API 也从 Java EE 升级为 Jakarta EE。 简单来说,您需要将所有 javax 的 imports 都替换为 jakarta。具体如下: javax.persistence.* -> jakarta.persistence.* javax.validation.* -> jakarta.validation.* javax.servlet.* -> jakarta.servlet.* javax.annotation.* -> jakarta.annotation.* javax.transaction.* -> jakarta.transaction.* 换mybatis依赖 Invalid value type for attribute ‘factoryBeanObjectType‘: java.lang.String 所以升级 Mybatis-Plus 版本为 3.5.5 版本即可,需要注意下 Maven 的坐标标识 是mybatis-plus-spring-boot3-starter,这点和SpringBoot 2 的依赖坐标mybatis-plus-boot-starter有所区别 第一步:注释spring-boot-starter <!-- <dependency>--> <!-- <groupId>com.baomidou</groupId>--> <!-- <artifactId>mybatis-plus-boot-starter</artifactId>--> <!-- <version>${mybatis.plus.version}</version>--> <!-- </dependency>--> 第二步:引入新的依赖 <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-spring-boot3-starter</artifactId> <version>3.5.5</version> </dependency> 第三步 <dependencyManagement> <dependencies> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis-spring</artifactId> <version>3.0.3</version> </dependency> </dependencies> </dependencyManagement> 动态数据源修改 第一步注释如下代码 <dependency> <groupId>com.baomidou</groupId> <artifactId>dynamic-datasource-spring-boot-starter</artifactId> <version>3.5.0</version> </dependency> 第二步:引入依赖 <dependency> <groupId>com.baomidou</groupId> <artifactId>dynamic-datasource-spring-boot3-starter</artifactId> <version>4.2.0</version> </dependency> -
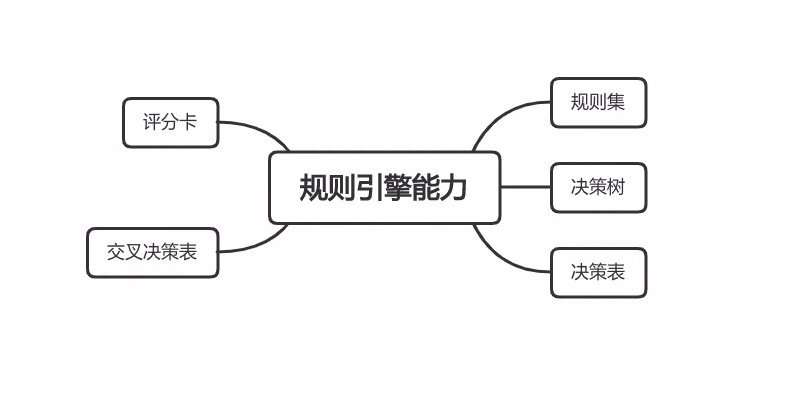
聊一聊规则引擎 规则引擎能力 一、规则集 规则集也叫决策集,是由一组普通规则和循环规则构成的规则集合,是使用频率最高的一种业务规则实现方式。 鲁班提供循环、逻辑(IF/ELSE)、赋值、执行、跳出规则等指令。 经典实例 新用户注册优惠: 如果用户是新注册用户,并且首次购买订单金额超过一定数额,则发送一张10%折扣的优惠券。 购物满减优惠: 如果用户购物车中的商品总价达到一定金额阈值,则自动应用满减优惠。比如,购物车金额大于100元可以享受减免10元的优惠。 特定商品优惠: 如果用户购买特定商品(如促销商品、季节性商品),则提供针对该商品额外的折扣或优惠。 生日优惠券: 在用户生日时发送一张生日优惠券,提供额外的折扣或者赠送特定商品。 用户活跃度奖励: 对于长时间未下单的用户,发送特定额度的优惠券以鼓励再次购买。 地理位置优惠: 针对特定地理位置的用户发送定向的优惠券,以促进当地的销售。 病人风险评估系统规则集示例 考虑以下条件和操作: 年龄: 30岁以下(Young)、30到50岁(Middle-aged)、50岁以上(Elderly)。 生活方式: 锻炼频率(High、Moderate、Low)、饮食习惯(Healthy、Unhealthy)。 慢性病史: 有(Yes)或无(No)。 风险评估等级: 低风险(Low)、中风险(Moderate)、高风险(High)。 规则集示例: FOR(用户集合 ) 用户。年龄 IF 年龄 = Elderly AND (锻炼频率 = Low OR 饮食习惯 = Unhealthy) THEN 风险评估等级 = 高风险 IF 年龄 = Middle-aged AND 慢性病史 = Yes THEN 风险评估等级 = 高风险 IF 年龄 = Young AND 锻炼频率 = High THEN 风险评估等级 = 低风险 IF 年龄 = Elderly AND 锻炼频率 = Moderate THEN 风险评估等级 = 中风险 在这个例子中,规则集根据病人的年龄、生活方式和慢性病史等条件制定了不同的风险评估规则。例如,对于年龄较大且锻炼频率低或饮食不健康的病人,系统会评估其为高风险群体,需要更频繁的检查或干预措施。 这种规则集的应用有助于医疗保健领域更精准地对病人进行风险评估,并根据其个体情况提供相应的医疗建议,从而改善病人的健康状况。 二、决策树 决策树又称为规则树,规则引擎中提供的另外一种构建规则的方式,它以一棵树形结构来表现规则,决策树表现业务规则更为形象,其中每个节点代表一个测试条件,每个分支代表一个测试结果,而每个叶子节点包含一个决策结果。 信用评分系统决策树示例 考虑以下特征和目标: 年龄: 25岁以下(Young)、25到40岁(Middle-aged)、40岁以上(Elderly)。 收入水平: 低收入(Low)、中等收入(Medium)、高收入(High)。 信用历史: 良好(Good)、一般(Fair)、差劣(Poor)。 是否有抵押物: 有(Yes)或无(No)。 信用申请结果: 批准(Approved)或拒绝(Rejected)。 决策树示例: IF 信用历史 = 良好 AND 收入水平 = 高收入 THEN 信用申请结果 = 批准 ELSE IF 信用历史 = 良好 AND 收入水平 = 中等收入 THEN 信用申请结果 = 批准 ELSE IF 信用历史 = 一般 AND 是否有抵押物 = 有 THEN 信用申请结果 = 批准 ELSE IF 信用历史 = 一般 AND 是否有抵押物 = 无 THEN 信用申请结果 = 拒绝 ELSE IF 信用历史 = 差劣 THEN 信用申请结果 = 拒绝 在这个例子中,决策树根据申请者的年龄、收入水平、信用历史和是否有抵押物等特征,自动判断信用申请的结果。例如,如果申请者信用历史良好且收入水平高,那么系统会批准其信用申请;而如果信用历史一般但有抵押物,同样会批准。 这种决策树的应用使得信用评分系统能够自动化、可解释地做出信用决策,提高了效率同时保持了透明度。 三、决策表 决策表是一种以表格形式表现规则的工具,它非常适用于描述处理判断条件较多,各条件又相互组合、有多种决策方案的情况,决策表提供精确而简洁描述复杂逻辑的方式。 视图 使用excel 决策表的应用场景: 业务规则管理: 用于管理和维护大量的业务规则,使得业务规则的管理更加简便和直观。 风险评估: 在金融领域,可以使用决策表来定义风险评估规则,根据客户的不同特征进行信用评级。 产品定价: 在销售领域,可以使用决策表来制定产品定价策略,根据市场条件和产品特性进行灵活的定价。 合规性检查: 在法务和合规性领域,决策表可以用于定义符合法规的业务行为,确保组织的合规性。 推荐系统: 在电商领域,可以使用决策表来定义推荐算法的规则,根据用户的行为和喜好推荐相应的产品 电子商务促销活动管理系统决策表示例 假设我们有以下条件和操作: 用户类型: 普通用户(Regular)和会员用户(Premium)。 购物车金额: 低于100元(Low)和100元及以上(High)。 商品类别: 电子产品(Electronics)、服装(Apparel)、食品(Food)。 促销策略: 折扣(Discount)、满减(Cashback)、免费赠品(Free Gift)。 决策表: 用户类型 购物车金额 商品类别 触发促销策略 操作 普通用户 低金额 电子产品 折扣 应用10%折扣 普通用户 低金额 服装 满减 满200减20 普通用户 高金额 食品 免费赠品 赠送一份免费小吃 会员用户 高金额 电子产品 满减 满500减50 会员用户 低金额 服装 折扣 应用15%折扣 会员用户 高金额 食品 免费赠品 赠送一份免费礼包 在这个例子中,决策表根据用户类型、购物车金额和商品类别等条件定义了不同的促销策略。例如,对于普通用户购买低金额的电子产品,系统会应用10%的折扣;而对于会员用户购买高金额的电子产品,系统则会提供满减优惠。 这样的决策表使得促销活动管理系统能够根据多个条件智能地选择适当的促销策略,提高销售效果和用户满意度。 四、交叉决策表 交叉决策表又叫决策矩阵,是一种特殊类型的决策表。 与普通决策表相比,交叉决策表的条件由纵向和横向两个维度决定,而普通决策表的条件只是由纵向维度决定;但在普通决策表的动作部分可以是三种类型,分别是赋值、输出和执行方式,而在交叉决策表中动作部分就是纵向和横向两个维度交叉后的单元格的值,一般来说,这种交叉后单元格的值都是赋给某个变量或参数,所以交叉决策表的动作基本就一个,那就是赋值。 实际业务场景 假设我们正在开发一个智能家居系统,通过交叉决策表来确定何时触发不同设备的自动化操作。以下是一个简化的实际应用场景: 智能家居系统交叉决策表示例 考虑以下几个条件和设备: 时间段: 白天(Daytime)和夜晚(Nighttime)。 人员在家: 有人在家(Occupied)和无人在家(Unoccupied)。 光照程度: 光线充足(Well-lit)和光线不足(Dimly-lit)。 设备: 灯光(Lights)、温控器(Thermostat)、安全摄像头(Security Camera)。 交叉决策表: 时间段 人员在家 光照程度 触发设备 操作 白天 有人 光线充足 无 保持设备关闭 白天 有人 光线不足 灯光 打开灯光 白天 无人 无 灯光、温控器 打开灯光、调整温度 夜晚 有人 光线充足 无 保持设备关闭 夜晚 有人 光线不足 灯光 打开灯光 夜晚 无人 无 安全摄像头 打开安全摄像头 在这个例子中,交叉决策表综合考虑了时间段、人员在家与否以及光照程度等多个条件。根据这些条件的不同组合,系统可以智能地触发相应的设备操作,使智能家居系统更符合用户的实际需求。例如,在夜晚、有人在家、光线不足的情况下,系统可以自动打开灯光,提高家居的舒适性和安全性。 五、评分卡 评分是对个人或机构的相关信息进行分析之后的一种数值表达,表示此人或此机构由于信用活动的拒付行为所造成损失风险的可能性,评分通常用于对个人或机构的风险管理与评估。 假设我们正在构建一个贷款评分系统,使用评分卡来评估个人信用并决定是否批准其贷款申请。以下是一个简化的实际应用场景: 贷款评分卡示例 考虑以下特征和分数分配: 年龄: 20岁以下(0分)、20到30岁(10分)、30到40岁(20分)、40岁以上(30分)。 收入水平: 低收入(0分)、中等收入(15分)、高收入(30分)。 信用历史: 良好(30分)、一般(15分)、差劣(0分)。 负债比例: 低于30%(20分)、30%到50%(10分)、50%以上(0分)。 工作年限: 不足一年(0分)、1到5年(10分)、5年以上(20分)。 评分卡示例: 总分 = 年龄分 + 收入分 + 信用历史分 + 负债比例分 + 工作年限分 IF 总分 >= 70 THEN 批准贷款 ELSE IF 50 <= 总分 < 70 THEN 需要进一步审查 ELSE 批准贷款 在这个例子中,评分卡通过对申请者的年龄、收入水平、信用历史、负债比例和工作年限等特征进行分数分配,计算出总分。然后,系统通过总分的阈值来决定是否批准贷款。例如,总分大于等于70分的申请者可以直接批准贷款,而总分在50到70之间的申请者需要进一步审查。 这种评分卡的应用使得贷款决策更加客观、可量化,有助于提高贷款审批的效率和一致性。 现有规则引擎在业务端使用评估 业务规则集适合简单IF - THEN逻辑业务和简单循环业务逻辑 决策树适合简单IF - ELSE 带分支的简单业务逻辑使用 复杂多条件场景想使用决策表或者评估卡来创建规则,更符合业务人员的使用习惯 如何使用规则引擎 sequenceDiagram participant BusinessUser as 业务人员 participant BusinessIT as 业务IT人员 participant Implementation as 公司实施人员 BusinessUser ->> BusinessIT: 请求创建具体规则 BusinessIT ->> Implementation: 使用规则引擎配置规则模板和规则包 Implementation ->> BusinessIT: 完成规则配置 BusinessIT ->> BusinessUser: 使用规则模板创建规则 BusinessUser ->> BusinessIT: 提出规则调整需求 BusinessIT ->> BusinessUser: 根据需求调整规则逻辑 BusinessUser ->> BusinessIT: 动态创建和维护规则 在整个Saas系统中,涉及到三个主要角色:业务人员、业务IT人员和公司实施人员。以下是每个角色在规则引擎使用过程中的主要职责: 公司实施人员 规则集、决策树、决策表、交叉决策表、评估卡的规则包创建: 负责使用规则引擎的界面或工具,创建和配置规则集、决策树、决策表、交叉决策表、评估卡的规则包,以便后续的规则模板和规则创建。 业务规则模板的创建: 设计和创建通用的业务规则模板,为业务IT人员提供规则创建的基础结构和规范。 业务IT人员 规则创建: 根据公司实施人员配置好的规则模板和知识包,使用规则引擎的工具创建具体的业务规则,包括规则集、决策树、决策表、交叉决策表、评估卡等。 规则逻辑调整: 负责根据业务需求对已创建的规则进行逻辑调整,确保规则符合业务规则模板和公司实施人员的要求。 规则维护: 定期检查和更新规则,确保规则引擎中的规则集和决策树等结构始终与业务要求保持一致。 业务人员 业务规则调整: 在规则引擎的用户界面中,根据业务需求直接调整已创建的规则,例如修改决策表的条件或调整评估卡的分数等。 规则逻辑优化: 根据业务实际运作的反馈,提出对规则逻辑的优化建议,协助业务IT人员进行调整。 规则动态创建和维护: 在业务变化时,通过规则引擎的界面灵活地创建和维护规则,确保系统能够快速响应业务的变化。 这样的角色划分和职责分配可以使得规则引擎的使用更具灵活性和适应性,不同层次的用户可以专注于其核心职责,共同完成规则的创建和维护。 定制化业务 部分更针对性业务模式由业务团队进行定制页面,如果需要更多定制指令由技术部开发
-
Flowable工作流引擎源码深度解析 Flowable工作流引擎源码深度解析 前言 Flowable是一个轻量级的业务流程引擎,基于BPMN 2.0规范实现,是Activiti项目的一个分支。作为Java生态中最流行的工作流引擎之一,了解其内部实现对于定制化开发和性能优化至关重要。本文将深入分析Flowable的核心源码结构和执行逻辑,帮助开发者更好地理解和使用这一强大工具。 核心架构概览 Flowable的源码主要分为以下几个核心模块: flowable-engine:核心引擎实现 flowable-bpmn-converter:BPMN模型转换器 flowable-process-validation:流程验证模块 flowable-image-generator:流程图生成模块 flowable-rest:REST API实现 其中,flowable-engine是最核心的部分,我们的分析也将主要集中在这个模块上。 ProcessEngine初始化流程 Flowable的入口是ProcessEngine接口,通常通过ProcessEngineConfiguration来创建。让我们看看其初始化过程: public class ProcessEngineConfigurationImpl extends ProcessEngineConfiguration { public ProcessEngine buildProcessEngine() { init(); ProcessEngineImpl processEngine = new ProcessEngineImpl(this); postProcessEngineInitialisation(); return processEngine; } public void init() { initCommandContextFactory(); initTransactionContextFactory(); initCommandExecutors(); initServices(); initDataSource(); initDbSchema(); initBeans(); initTransactionFactory(); // 其他初始化方法... } } 初始化过程主要包括: 初始化命令上下文工厂 初始化事务上下文工厂 初始化命令执行器 初始化各种服务 初始化数据源和数据库架构 初始化事务工厂等 这种设计遵循了良好的工厂模式和构建器模式。 命令模式的应用 Flowable大量使用了命令模式,所有对流程的操作都被封装为Command对象: public interface Command<T> { T execute(CommandContext commandContext); } 执行命令的是CommandExecutor,它主要有两个实现: CommandExecutorImpl:普通实现 TransactionCommandExecutor:带事务的实现 让我们看看CommandExecutorImpl的实现: public class CommandExecutorImpl implements CommandExecutor { protected CommandContextFactory commandContextFactory; protected TransactionContextFactory transactionContextFactory; public <T> T execute(Command<T> command) { CommandContext commandContext = commandContextFactory.createCommandContext(command); try { T result = command.execute(commandContext); commandContext.close(); return result; } catch (Exception e) { commandContext.exception(e); } finally { try { commandContext.close(); } catch (Exception e) { // 日志记录 } } return null; } } 这种设计确保了所有流程操作都在一个一致的上下文中执行,并且可以正确处理事务和异常。 流程定义加载 当我们部署一个BPMN文件时,Flowable会解析它并转换为内部模型。核心类是BpmnParser: public class BpmnParser { public BpmnParse createParse() { return new BpmnParse(this); } public BpmnParse parse(InputStream inputStream) { BpmnParse bpmnParse = createParse(); bpmnParse.sourceInputStream = inputStream; bpmnParse.execute(); return bpmnParse; } } BpmnParse类负责具体的解析逻辑: public class BpmnParse extends BpmnParseHandler { public BpmnParse execute() { try { // 解析XML文档 DocumentBuilderFactory dbf = XmlUtil.createSafeDocumentBuilderFactory(); Document document = dbf.newDocumentBuilder().parse(sourceInputStream); // 解析BPMN元素 parseRootElement(document.getDocumentElement()); // 处理流程定义 processDI(); // 完成解析 executeParse(); } catch (Exception e) { // 异常处理 } return this; } protected void parseRootElement(Element rootElement) { // 解析流程、任务、网关等元素 } } 这个过程将BPMN文件转换为ProcessDefinitionEntity对象,其中包含了流程的所有信息。 流程执行引擎 流程实例的执行由ExecutionEntity类负责: public class ExecutionEntity implements Execution, ExecutionListenerContainer { protected String id; protected ProcessDefinitionEntity processDefinition; protected String businessKey; protected String activityId; protected ExecutionEntity parent; protected List<ExecutionEntity> executions = new ArrayList<>(); // 其他属性... public void start() { CommandContext commandContext = Context.getCommandContext(); // 执行流程实例启动逻辑 // 触发事件监听器 // 执行第一个活动节点 } public void continueExecution() { ExecutionEntity execution = this; while (execution != null && execution.isActive()) { ActivityImpl activity = execution.getActivity(); if (activity != null) { // 执行当前活动节点 execution = activity.execute(execution); } else { // 已完成 execution = null; } } } } 每个流程实例都对应一个ExecutionEntity,每个并行流程也对应一个子ExecutionEntity。 任务管理 任务由TaskEntity类表示: public class TaskEntity implements Task { protected String id; protected String name; protected String description; protected String assignee; protected Date createTime; protected String executionId; protected String processInstanceId; // 其他属性... public void complete() { // 验证任务状态 // 执行任务完成逻辑 // 触发事件监听器 // 推进流程执行 } } 任务的创建、分配和完成都是通过TaskService接口实现的: public interface TaskService { Task newTask(); void saveTask(Task task); void deleteTask(String taskId); void claim(String taskId, String userId); void complete(String taskId); // 其他方法... } 事件监听机制 Flowable提供了丰富的事件监听机制,核心接口是FlowableEventListener: public interface FlowableEventListener { void onEvent(FlowableEvent event); boolean isFailOnException(); } 事件类型由FlowableEventType枚举定义,包括流程启动、任务创建、流程完成等多种类型。 事件的分发由FlowableEventDispatcher接口负责: public interface FlowableEventDispatcher { void addEventListener(FlowableEventListener listener); void addEventListener(FlowableEventListener listener, FlowableEventType... types); void removeEventListener(FlowableEventListener listener); void dispatchEvent(FlowableEvent event); } 这种设计允许我们在流程的各个阶段插入自定义逻辑。 数据持久化 Flowable使用MyBatis作为ORM框架进行数据持久化。核心接口是DbSqlSession: public class DbSqlSession implements Session { protected SqlSession sqlSession; protected DbSqlSessionFactory dbSqlSessionFactory; protected List<PersistentObject> insertedObjects = new ArrayList<>(); protected List<PersistentObject> updatedObjects = new ArrayList<>(); protected List<PersistentObject> deletedObjects = new ArrayList<>(); public void flush() { // 处理插入对象 for (PersistentObject insertedObject : insertedObjects) { String insertStatement = dbSqlSessionFactory.getInsertStatement(insertedObject); sqlSession.insert(insertStatement, insertedObject); } // 处理更新对象 for (PersistentObject updatedObject : updatedObjects) { String updateStatement = dbSqlSessionFactory.getUpdateStatement(updatedObject); sqlSession.update(updateStatement, updatedObject); } // 处理删除对象 for (PersistentObject deletedObject : deletedObjects) { String deleteStatement = dbSqlSessionFactory.getDeleteStatement(deletedObject); sqlSession.delete(deleteStatement, deletedObject); } // 清空缓存 insertedObjects.clear(); updatedObjects.clear(); deletedObjects.clear(); } } 所有实体对象的变更都会被记录在这些列表中,然后在事务提交时一次性写入数据库。 性能优化 Flowable做了许多性能优化,其中最重要的是缓存机制: public class DeploymentCache<T> { protected Map<String, T> cache = new HashMap<>(); protected int limit; protected LinkedList<String> keyList = new LinkedList<>(); public void add(String id, T obj) { if (limit > 0 && keyList.size() >= limit) { String oldestKey = keyList.removeFirst(); cache.remove(oldestKey); } cache.put(id, obj); keyList.addLast(id); } public T get(String id) { return cache.get(id); } public void remove(String id) { cache.remove(id); keyList.remove(id); } } 这种LRU缓存确保了频繁使用的流程定义可以快速获取,而不需要重复从数据库加载。 扩展点分析 Flowable提供了丰富的扩展点,允许开发者定制化流程行为: TaskListener:任务生命周期监听器 ExecutionListener:执行流程监听器 ActivityBehavior:自定义活动行为 ExpressionManager:表达式管理器 VariableType:自定义变量类型 以TaskListener为例: public interface TaskListener { String EVENTNAME_CREATE = "create"; String EVENTNAME_ASSIGNMENT = "assignment"; String EVENTNAME_COMPLETE = "complete"; String EVENTNAME_DELETE = "delete"; void notify(DelegateTask delegateTask); } 通过实现这个接口,我们可以在任务的各个生命周期阶段插入自定义逻辑。 异步执行器 Flowable 6引入了新的异步执行器,替代了旧的JobExecutor: public class DefaultAsyncExecutor implements AsyncExecutor { protected ThreadPoolExecutor threadPoolExecutor; protected RejectedExecutionHandler rejectedExecutionHandler; protected ThreadFactory threadFactory; public void start() { if (threadPoolExecutor == null) { threadPoolExecutor = new ThreadPoolExecutor( corePoolSize, maxPoolSize, keepAliveTime, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(queueSize), threadFactory, rejectedExecutionHandler ); } // 启动作业获取线程 startJobAcquisitionThread(); } protected void executeAsyncJob(Job job) { Runnable runnable = new ExecuteAsyncRunnable(job, this); threadPoolExecutor.execute(runnable); } } 这种设计使得Flowable可以高效地处理大量的异步任务。 我很乐意解释Flowable 6.x中如何实现动态加节点,并提供一个实用的demo。 在Flowable 6.x中,动态修改流程实例主要通过RuntimeService的API来实现,特别是通过createProcessInstanceModification方法。下面我将详细介绍实现方法并提供一个完整的示例。 package com.example.flowable; import org.flowable.engine.*; import org.flowable.engine.impl.cfg.StandaloneProcessEngineConfiguration; import org.flowable.engine.repository.Deployment; import org.flowable.engine.repository.ProcessDefinition; import org.flowable.engine.runtime.ProcessInstance; import org.flowable.task.api.Task; import java.util.HashMap; import java.util.List; import java.util.Map; /** * Flowable 6.x 动态添加节点示例 */ public class FlowableDynamicTaskDemo { public static void main(String[] args) { // 初始化流程引擎 ProcessEngine processEngine = initProcessEngine(); // 获取各种服务 RepositoryService repositoryService = processEngine.getRepositoryService(); RuntimeService runtimeService = processEngine.getRuntimeService(); TaskService taskService = processEngine.getTaskService(); // 部署流程定义 Deployment deployment = repositoryService.createDeployment() .addClasspathResource("dynamic-process.bpmn20.xml") .deploy(); ProcessDefinition processDefinition = repositoryService.createProcessDefinitionQuery() .deploymentId(deployment.getId()) .singleResult(); System.out.println("流程定义部署完成: " + processDefinition.getName()); // 启动流程实例 Map<String, Object> variables = new HashMap<>(); variables.put("applicant", "张三"); variables.put("amount", 5000); ProcessInstance processInstance = runtimeService.startProcessInstanceByKey("dynamicProcess", variables); System.out.println("流程实例启动成功,ID: " + processInstance.getId()); // 查询当前任务 Task currentTask = taskService.createTaskQuery() .processInstanceId(processInstance.getId()) .singleResult(); System.out.println("当前任务: " + currentTask.getName()); // 动态添加一个审核任务节点 System.out.println("开始动态添加节点..."); dynamicallyAddTask(runtimeService, processInstance.getId(), currentTask.getId()); // 完成当前任务 taskService.complete(currentTask.getId()); System.out.println("完成任务: " + currentTask.getName()); // 查看动态添加的任务 List<Task> tasks = taskService.createTaskQuery() .processInstanceId(processInstance.getId()) .list(); for (Task task : tasks) { System.out.println("当前活动任务: " + task.getName() + ", ID: " + task.getId()); // 完成动态添加的任务 taskService.complete(task.getId()); System.out.println("完成任务: " + task.getName()); } // 检查流程是否结束 ProcessInstance runningInstance = runtimeService.createProcessInstanceQuery() .processInstanceId(processInstance.getId()) .singleResult(); if (runningInstance == null) { System.out.println("流程实例已完成"); } else { System.out.println("流程实例仍在运行"); } } /** * 动态添加任务节点 */ private static void dynamicallyAddTask(RuntimeService runtimeService, String processInstanceId, String activityId) { runtimeService.createProcessInstanceModification(processInstanceId) .startBeforeActivity(activityId) // 在当前活动前启动 .addExecution() // 添加一个执行分支 .callActivity("dynamicTask") // 调用一个动态任务活动 .setVariable("reviewer", "李四") // 设置变量 .setVariable("dynamicTaskName", "财务经理审核") // 动态任务名称 .execute(); System.out.println("动态任务添加成功"); } /** * 初始化流程引擎 */ private static ProcessEngine initProcessEngine() { ProcessEngineConfiguration cfg = new StandaloneProcessEngineConfiguration() .setJdbcUrl("jdbc:h2:mem:flowable;DB_CLOSE_DELAY=-1") .setJdbcUsername("sa") .setJdbcPassword("") .setJdbcDriver("org.h2.Driver") .setDatabaseSchemaUpdate(ProcessEngineConfiguration.DB_SCHEMA_UPDATE_TRUE); return cfg.buildProcessEngine(); } } <?xml version="1.0" encoding="UTF-8"?> <definitions xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:flowable="http://flowable.org/bpmn" targetNamespace="http://www.flowable.org/processdef"> <process id="dynamicProcess" name="动态节点示例流程" isExecutable="true"> <startEvent id="startEvent" name="开始"/> <sequenceFlow id="flow1" sourceRef="startEvent" targetRef="firstTask"/> <userTask id="firstTask" name="部门经理审批" flowable:assignee="${applicant}"> <documentation>申请金额: ${amount}</documentation> </userTask> <sequenceFlow id="flow2" sourceRef="firstTask" targetRef="dynamicTask"/> <userTask id="dynamicTask" name="动态任务" flowable:assignee="${reviewer}"> <documentation>这是一个可以被动态添加的任务节点</documentation> </userTask> <sequenceFlow id="flow3" sourceRef="dynamicTask" targetRef="endEvent"/> <endEvent id="endEvent" name="结束"/> </process> </definitions> 在Flowable 6.x中动态添加节点主要有以下几种方法: 主要方法 流程实例修改 - 通过RuntimeService提供的API: runtimeService.createProcessInstanceModification(processInstanceId) .startBeforeActivity("activityId") // 在指定活动前启动 .execute(); 动态子流程注入 - 在运行时动态添加子流程: runtimeService.createProcessInstanceModification(processInstanceId) .addExecution() .callActivity("subProcessId") .execute(); 动态创建活动 - 直接创建和执行新活动: runtimeService.createProcessInstanceModification(processInstanceId) .startBeforeActivity("userTaskId") .setVariable("assignee", "动态分配的用户") .execute(); 使用场景 动态添加节点在以下场景特别有用: 基于业务规则动态调整审批流程 根据申请金额/内容添加额外的审核步骤 特殊情况下插入临时审核/处理节点 灵活处理流程异常情况 实现要点 确保节点ID唯一性:动态添加的节点必须有唯一的ID 维护执行链的完整性:确保流程能正确流转 变量传递:为动态节点设置必要的流程变量 权限管理:动态添加的任务需要正确分配处理人 注意事项 过度使用动态节点会使流程追踪和维护变得困难 动态节点可能不会显示在流程图上,需要额外的审计记录 升级到Flowable 7时,部分API可能会有变化 确保动态添加的节点在流程异常时能够被正确处理 这个示例展示了如何在Flowable 6.x版本中动态添加一个审核任务节点。你可以根据实际需求调整代码,例如添加多个节点、条件节点或并行节点。 结论 通过深入分析Flowable的源码,我们可以看到它采用了许多优秀的设计模式: 命令模式:封装所有流程操作 工厂模式:创建各种对象 构建器模式:配置引擎 策略模式:不同的活动行为 观察者模式:事件监听机制 这些设计使得Flowable既灵活又强大,能够适应各种复杂的业务流程需求。同时,它的性能优化策略也确保了在高负载环境下的稳定运行。 对于想要深入了解工作流引擎实现的开发者,Flowable的源码提供了一个很好的学习案例。通过理解其内部机制,我们可以更好地使用和扩展这个强大的引擎。 参考资源 Flowable GitHub仓库:https://github.com/flowable/flowable-engine Flowable官方文档:https://www.flowable.org/docs/userguide/index.html BPMN 2.0规范:https://www.omg.org/spec/BPMN/2.0/
-
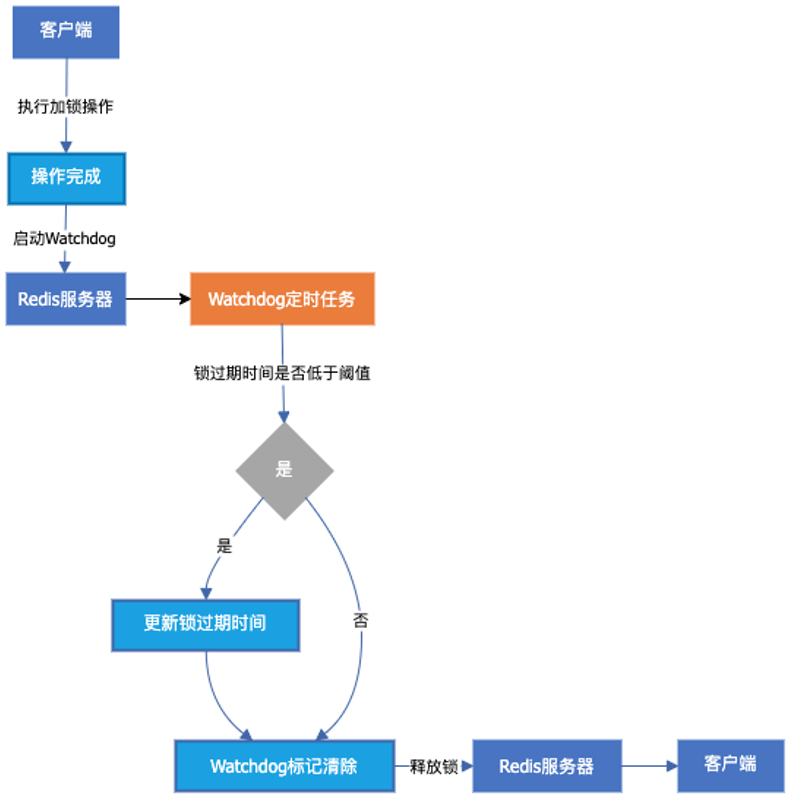
分布式锁如何自动续期(Watchdog 机制解析) 分布式锁如何自动续期(Watchdog 机制解析) 在分布式系统中,分布式锁广泛应用于防止多个进程同时操作共享资源。其中,基于 Redis 的分布式锁(如 Redisson)提供了一种高效的实现方式。然而,锁的超时管理是一个关键问题:如果业务执行时间较长,锁可能会在任务完成前过期,从而导致多个客户端同时持有锁,造成数据竞争。为了解决这个问题,我们可以使用 Watchdog(看门狗)机制,实现分布式锁的自动续期。 1. 分布式锁的基本流程 以 Redis 为例,分布式锁的获取和释放流程通常如下: 客户端1 发送 SET lock_key unique_id NX PX 30000 请求,尝试获取锁。 Redis 服务器 存储 lock_key,过期时间设定为 30 秒。 客户端1 成功获取锁,开始执行任务。 如果任务在 30 秒内完成,客户端1 发送 DEL lock_key 释放锁。 其他客户端(如 客户端2)在锁释放后才能成功获取锁。 上述流程有一个关键问题:如果 客户端1 任务执行时间超过 30 秒,但还未完成,锁会被 Redis 自动删除,从而导致其他客户端获取锁,出现并发问题。 2. Watchdog 机制的作用 为了解决锁过期的问题,Redisson 等库引入了 Watchdog 机制。Watchdog 的基本原理如下: 客户端1 获取锁后,启动 Watchdog 线程,每隔 lockLeaseTime / 3 秒(例如 10 秒)检查锁是否仍然持有。 如果 客户端1 仍然活跃,则自动向 Redis 发送 PEXPIRE lock_key 30000 请求,延长锁的有效期。 当 客户端1 任务执行完成 时,主动调用 DEL lock_key 释放锁。 如果 客户端1 进程崩溃,Watchdog 不会继续续期,锁会在到期后自动释放。 3. Watchdog 续期的流程示意 根据你的流程图,分布式锁 Watchdog 续期的流程如下: 客户端1 获取锁(SET lock_key unique_id NX PX 30000)。 客户端1 启动 Watchdog 线程,间隔 10 秒检查锁状态。 Watchdog 检查 Redis 是否仍然持有 lock_key。 如果 lock_key 仍然属于 客户端1,执行 PEXPIRE lock_key 30000 延长锁的有效期。 如果 客户端1 任务完成,调用 DEL lock_key 释放锁,Watchdog 线程退出。 如果 客户端1 进程意外终止,Watchdog 失效,锁超时后自动释放。 4. Watchdog 机制的优缺点 优点 自动续期:任务执行时间不确定时,确保锁不会过早释放。 进程故障自动释放:如果进程崩溃,锁在超时后自动释放,避免死锁。 减少人为干预:无需手动计算任务时间,提高系统健壮性。 缺点 需要持久化心跳检测:Watchdog 线程需要定期与 Redis 通信,增加了 Redis 负载。 续期间隔需优化:如果 Watchdog 续期间隔过长,锁可能仍然会过期。 5. 代码示例(基于 Redisson) // 创建 Redisson 客户端 RedissonClient redisson = Redisson.create(); // 获取分布式锁 RLock lock = redisson.getLock("myLock"); boolean locked = lock.tryLock(10, 30, TimeUnit.SECONDS); if (locked) { try { // 执行业务逻辑 System.out.println("业务处理中..."); Thread.sleep(40000); // 模拟业务执行超时 } finally { // 释放锁 lock.unlock(); } } 在 Redisson 中,如果 lock.tryLock() 仅传递 租约时间 lockLeaseTime,则默认会启用 Watchdog 机制,自动续期,直到 unlock() 被调用。 6. 总结 Watchdog 机制通过定期续约,避免 Redis 锁过期导致的并发问题。 适用于执行时间不确定的任务,能够在任务完成前自动续期。 需要权衡 Watchdog 续期频率和 Redis 负载,以优化性能。 如果你的业务场景对分布式锁有较高的可靠性要求,建议使用 Redisson 内置的 Watchdog 机制,而非手动管理锁的生命周期。
-
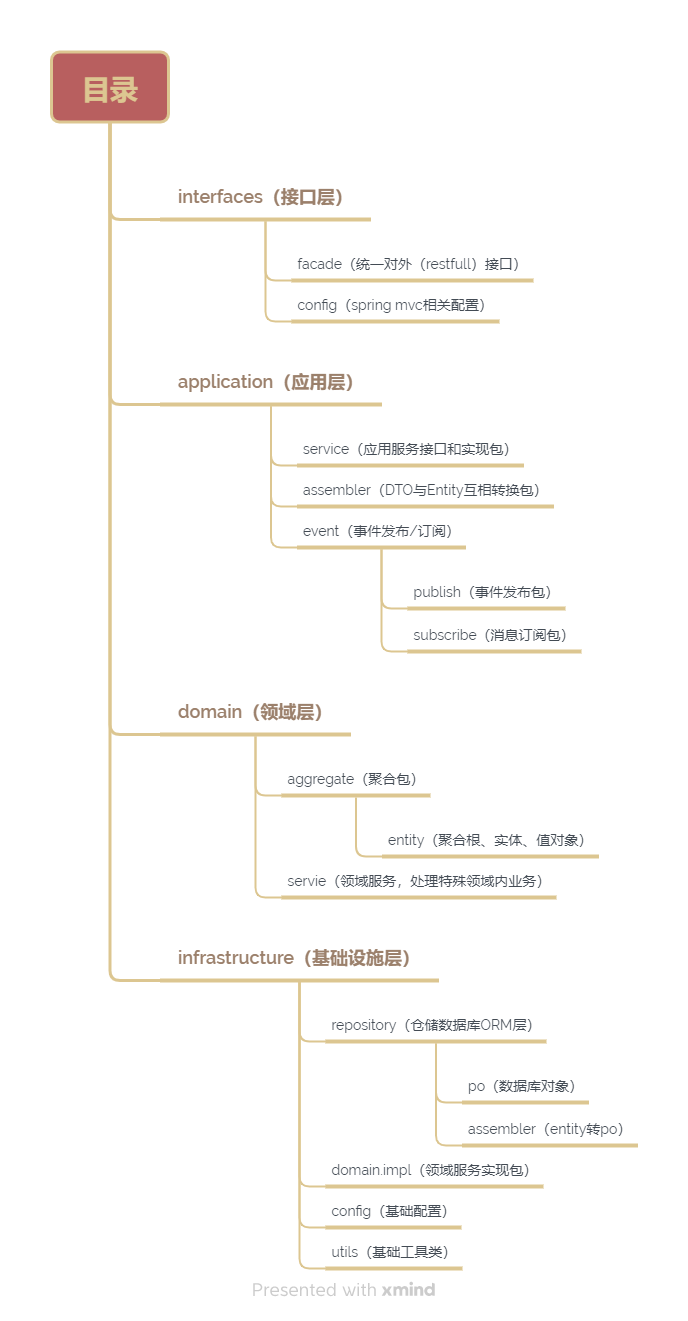
DDD业务服务的目录规划 DDD架构下的工程目录结构划分详解 在领域驱动设计(Domain-Driven Design, DDD)中,合理的工程目录结构对于实现复杂业务逻辑的清晰组织至关重要。本文将详细介绍基于DDD思想的工程目录划分方案,帮助开发团队更好地组织代码,提高系统的可维护性和可扩展性。 DDD工程目录的四层架构 根据思维导图所示,一个标准的DDD架构通常分为四个主要层次: 1. 接口层(interfaces) 接口层是系统与外部交互的门户,负责处理来自外部的请求,并将请求转发到应用层。 facade(统一对外接口):提供RESTful API接口,处理HTTP请求和响应 config(spring mvc相关配置):包含接口层相关的配置,如控制器配置、请求拦截器等 src/main/java/com/company/project/interfaces/ ├── facade/ # 外观模式,统一接口 │ ├── dto/ # 数据传输对象 │ ├── assembler/ # DTO与领域对象转换 │ └── controller/ # 控制器 └── config/ # 接口层配置 2. 应用层(application) 应用层是业务流程的协调者,负责组织领域对象完成特定的应用功能。 service(应用服务接口和实现包):协调领域对象完成业务流程 assembler(DTO与Entity互相转换包):负责应用层与领域层数据模型的相互转换 event(事件发布/订阅) : publish(事件发布包):发布领域事件 subscribe(消息订阅包):订阅并处理领域事件 src/main/java/com/company/project/application/ ├── service/ # 应用服务 │ ├── impl/ # 应用服务实现 │ └── dto/ # 应用服务数据传输对象 ├── assembler/ # DTO与领域对象转换 └── event/ # 事件处理 ├── publish/ # 事件发布 └── subscribe/ # 事件订阅 3. 领域层(domain) 领域层是业务核心,包含业务规则和逻辑。 aggregate(聚合包) :聚合是一组关联的实体和值对象的集合 entity(聚合根、实体、值对象):领域模型核心元素 service(领域服务,处理特殊领域内业务):处理跨实体的业务逻辑 src/main/java/com/company/project/domain/ ├── aggregate/ # 聚合 │ ├── order/ # 订单聚合(示例) │ │ ├── Order.java # 聚合根 │ │ ├── OrderItem.java # 实体 │ │ ├── OrderStatus.java # 值对象 │ │ └── OrderRepository.java # 仓储接口 │ └── user/ # 用户聚合(示例) └── service/ # 领域服务 └── impl/ # 领域服务实现 4. 基础设施层(infrastructure) 基础设施层为其他层提供技术支持。 repository(仓储数据库ORM层) : po(数据库对象):数据库表映射对象 assembler(entity转po):领域对象与数据库对象转换 domain.impl(领域服务实现包):领域服务的具体实现 config(基础配置):系统基础配置 utils(基础工具类):通用工具类 src/main/java/com/company/project/infrastructure/ ├── repository/ # 仓储实现 │ ├── po/ # 持久化对象 │ ├── assembler/ # 领域对象与持久化对象转换 │ ├── mapper/ # MyBatis映射接口 │ └── impl/ # 仓储接口实现 ├── domain/ # 领域层实现 │ └── impl/ # 领域服务实现类 ├── config/ # 基础配置 └── utils/ # 工具类 目录结构的实践建议 按领域划分而非技术功能:在DDD中,首先应该按照业务领域进行划分,而非按照技术功能(如controller、service、dao等) 考虑限界上下文:不同的业务上下文应该有清晰的边界,可以在目录结构中体现 聚合根作为目录划分的基础:每个聚合根可以作为一个子目录,包含相关的实体和值对象 保持领域逻辑的纯净:领域层不应依赖其他层,特别是不应依赖基础设施层 接口与实现分离:定义清晰的接口,并将实现放在适当的包中 示例目录结构(电子商务系统) src/main/java/com/ecommerce/ ├── interfaces/ │ ├── facade/ │ │ ├── order/ # 订单接口 │ │ └── product/ # 产品接口 │ └── config/ # 接口配置 ├── application/ │ ├── service/ │ │ ├── order/ # 订单应用服务 │ │ └── product/ # 产品应用服务 │ ├── assembler/ # DTO转换器 │ └── event/ │ ├── publish/ # 事件发布 │ └── subscribe/ # 事件订阅 ├── domain/ │ ├── aggregate/ │ │ ├── order/ # 订单聚合 │ │ ├── product/ # 产品聚合 │ │ └── user/ # 用户聚合 │ └── service/ # 领域服务 └── infrastructure/ ├── repository/ │ ├── po/ # 持久化对象 │ ├── assembler/ # 对象转换 │ └── impl/ # 仓储实现 ├── domain/ # 领域实现 ├── config/ # 系统配置 └── utils/ # 工具类 结语 DDD在项目中的应用还有待进一步验证,记录一下DDD业务服务的规划。