搜索到
88
篇与
的结果
-
 一句话概括下spring框架及spring cloud框架主要组件 Spring框架及Spring Cloud框架主要组件概括 Spring是Java领域的主流技术框架集合,包含众多项目: Spring顶级项目: Spring IO platform:用于系统部署,是可集成的现代化应用版本平台,在使用maven dependency引入spring jar包时发挥作用。 Spring Boot:简化产品级Spring应用和服务创建,简化配置文件,用嵌入式web服务器,含开箱即用微服务功能,可与spring cloud联合部署。 Spring Framework:即通常说的spring框架,开源的Java/Java EE全功能栈应用程序框架,其他spring项目如spring boot依赖于此。 Spring Cloud:微服务工具包,提供分布式系统的配置管理、服务发现、断路器、智能路由等开发工具包。 Spring XD:运行时环境(服务器软件,非开发框架),组合spring技术采集和处理大数据。 Spring Data:数据访问及操作工具包,封装多种数据及数据库访问技术。 Spring Batch:批处理框架,具备任务调度、日志记录/跟踪等功能。 Spring Security:为基于Spring的企业应用提供声明式安全访问控制解决方案。 Spring Integration:面向企业应用集成的编程框架,支持多种通信方式。 Spring Social:连接社交服务API的工具包,可连接如Twitter、Facebook等。 Spring AMQP:消息队列操作工具包,主要封装RabbitMQ操作。 Spring HATEOAS:支持实现超文本驱动的REST Web服务的开发库。 Spring Mobile:Spring MVC的扩展,简化手机上Web应用开发。 Spring for Android:Spring框架扩展,简化Android本地应用开发,提供RestTemplate访问Rest服务。 Spring Web Flow:管理Web应用页面流程,将页面跳转流程单独管理并可配置。 Spring LDAP:操作LDAP的Java工具包,基于Spring的JdbcTemplate模式简化LDAP访问。 Spring Session:session管理工具包,可将session保存到redis等进行集群化管理。 Spring Web Services:基于Spring的Web服务框架,提供SOAP服务开发,支持多种方式创建Web服务。 Spring Shell:提供交互式Shell,可用简单Spring编程模型开发命令。 Spring Roo:Spring开发辅助工具,用命令行生成自动化项目。 Spring Scala:为Scala语言编程提供spring框架封装。 Spring BlazeDS Integration:开发RIA工具包,可集成Adobe Flex、BlazeDS、Spring及Java技术创建RIA。 Spring Loaded:实现java程序和web应用热部署的开源工具。 Spring REST Shell:调用Rest服务的命令行工具。 目前Spring主要聚焦于Spring Boot(用于开发微服务)和Spring Cloud相关框架开发,Spring Cloud子项目包括: Spring Cloud Config:配置管理开发工具包,支持将配置放远程服务器,支持本地存储、Git及Subversion。 Spring Cloud Bus:事件、消息总线,在集群中传播状态变化,可与Spring Cloud Config联合实现热部署。 Spring Cloud Netflix:针对多种Netflix组件的开发工具包,含Eureka、Hystrix、Zuul、Archaius等。 Netflix Eureka:云端负载均衡,基于REST服务,用于定位服务,实现负载均衡和故障转移。 Netflix Hystrix:容错管理工具,控制服务和第三方库节点,增强容错能力。 Netflix Zuul:边缘服务工具,提供动态路由、监控等功能。 Netflix Archaius:配置管理API,含系列配置管理API,提供多种功能。 Spring Cloud for Cloud Foundry:通过Oauth2协议绑定服务到CloudFoundry(开源PaaS云平台)。 Spring Cloud Sleuth:日志收集工具包,封装Dapper、Zipkin和HTrace操作。 Spring Cloud Data Flow:大数据操作工具,通过命令行操作数据流。 Spring Cloud Security:安全工具包,为应用添加OAuth2安全控制。 Spring Cloud Consul:封装Consul操作,Consul是服务发现与配置工具,可与Docker容器无缝集成。 Spring Cloud Zookeeper:操作Zookeeper的工具包,用于服务注册和发现。 Spring Cloud Stream:数据流操作开发包,封装与Redis、Rabbit、Kafka等发送接收消息操作。 Spring Cloud CLI:基于Spring Boot CLI,可命令行快速建立云组件。
一句话概括下spring框架及spring cloud框架主要组件 Spring框架及Spring Cloud框架主要组件概括 Spring是Java领域的主流技术框架集合,包含众多项目: Spring顶级项目: Spring IO platform:用于系统部署,是可集成的现代化应用版本平台,在使用maven dependency引入spring jar包时发挥作用。 Spring Boot:简化产品级Spring应用和服务创建,简化配置文件,用嵌入式web服务器,含开箱即用微服务功能,可与spring cloud联合部署。 Spring Framework:即通常说的spring框架,开源的Java/Java EE全功能栈应用程序框架,其他spring项目如spring boot依赖于此。 Spring Cloud:微服务工具包,提供分布式系统的配置管理、服务发现、断路器、智能路由等开发工具包。 Spring XD:运行时环境(服务器软件,非开发框架),组合spring技术采集和处理大数据。 Spring Data:数据访问及操作工具包,封装多种数据及数据库访问技术。 Spring Batch:批处理框架,具备任务调度、日志记录/跟踪等功能。 Spring Security:为基于Spring的企业应用提供声明式安全访问控制解决方案。 Spring Integration:面向企业应用集成的编程框架,支持多种通信方式。 Spring Social:连接社交服务API的工具包,可连接如Twitter、Facebook等。 Spring AMQP:消息队列操作工具包,主要封装RabbitMQ操作。 Spring HATEOAS:支持实现超文本驱动的REST Web服务的开发库。 Spring Mobile:Spring MVC的扩展,简化手机上Web应用开发。 Spring for Android:Spring框架扩展,简化Android本地应用开发,提供RestTemplate访问Rest服务。 Spring Web Flow:管理Web应用页面流程,将页面跳转流程单独管理并可配置。 Spring LDAP:操作LDAP的Java工具包,基于Spring的JdbcTemplate模式简化LDAP访问。 Spring Session:session管理工具包,可将session保存到redis等进行集群化管理。 Spring Web Services:基于Spring的Web服务框架,提供SOAP服务开发,支持多种方式创建Web服务。 Spring Shell:提供交互式Shell,可用简单Spring编程模型开发命令。 Spring Roo:Spring开发辅助工具,用命令行生成自动化项目。 Spring Scala:为Scala语言编程提供spring框架封装。 Spring BlazeDS Integration:开发RIA工具包,可集成Adobe Flex、BlazeDS、Spring及Java技术创建RIA。 Spring Loaded:实现java程序和web应用热部署的开源工具。 Spring REST Shell:调用Rest服务的命令行工具。 目前Spring主要聚焦于Spring Boot(用于开发微服务)和Spring Cloud相关框架开发,Spring Cloud子项目包括: Spring Cloud Config:配置管理开发工具包,支持将配置放远程服务器,支持本地存储、Git及Subversion。 Spring Cloud Bus:事件、消息总线,在集群中传播状态变化,可与Spring Cloud Config联合实现热部署。 Spring Cloud Netflix:针对多种Netflix组件的开发工具包,含Eureka、Hystrix、Zuul、Archaius等。 Netflix Eureka:云端负载均衡,基于REST服务,用于定位服务,实现负载均衡和故障转移。 Netflix Hystrix:容错管理工具,控制服务和第三方库节点,增强容错能力。 Netflix Zuul:边缘服务工具,提供动态路由、监控等功能。 Netflix Archaius:配置管理API,含系列配置管理API,提供多种功能。 Spring Cloud for Cloud Foundry:通过Oauth2协议绑定服务到CloudFoundry(开源PaaS云平台)。 Spring Cloud Sleuth:日志收集工具包,封装Dapper、Zipkin和HTrace操作。 Spring Cloud Data Flow:大数据操作工具,通过命令行操作数据流。 Spring Cloud Security:安全工具包,为应用添加OAuth2安全控制。 Spring Cloud Consul:封装Consul操作,Consul是服务发现与配置工具,可与Docker容器无缝集成。 Spring Cloud Zookeeper:操作Zookeeper的工具包,用于服务注册和发现。 Spring Cloud Stream:数据流操作开发包,封装与Redis、Rabbit、Kafka等发送接收消息操作。 Spring Cloud CLI:基于Spring Boot CLI,可命令行快速建立云组件。 -
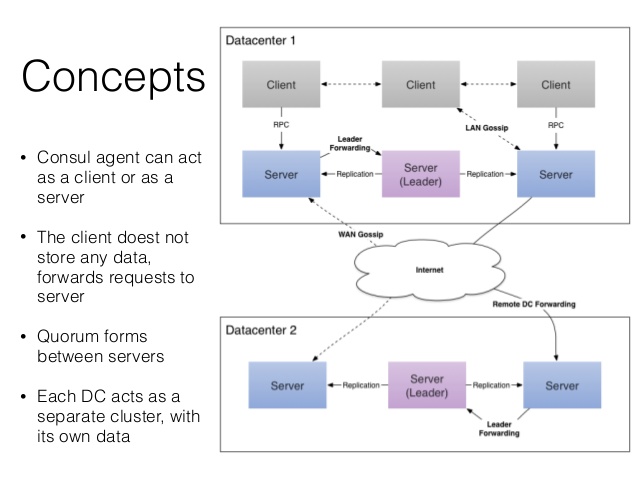
consul 入门 服务管理软件相关知识 1. 概述 一个支持多数据中心下,分布式高可用的服务管理软件,具备服务发现和配置共享功能。以consul为例,consul支持健康检查,允许存储键值对,一致性协议采用Raft算法保证服务高可用,成员管理和消息广播采用GOSSIP协议,支持ACL访问控制。 ACL技术在路由器中广泛采用,是基于包过滤的流控制技术,控制列表以源地址、目的地址及端口号为基本检查元素,规定符合条件的数据包是否允许通过。 gossip是p2p协议,去中心化,模拟人类传播谣言行为,有种子节点,种子节点每秒随机向其他节点发送自己的节点列表及要传播的消息,新加入节点能很快被全网知晓。 服务注册是一个服务将其位置信息在“中心注册节点”注册的过程,一般会注册主机IP地址、端口号,有时还有服务访问认证信息、使用协议、版本号及环境细节信息。 服务发现可让应用或组件发现其运行环境及其他应用或组件的信息,用户配置服务发现工具可分离实际容器与运行配置,常见配置信息有ip、端口号、名称等。当服务存在于多个主机节点上时,传统用静态配置实现服务信息注册,复杂系统中,为避免服务中断,动态的服务注册和发现很重要。 相关开源项目有Zookeeper,Doozer,Etcd等强一致性项目,主要用于服务间协调,也可用于服务注册。 强一致性协议是按照某一顺序串行执行存储对象读写操作,更新存储对象后,后续访问总是读到最新值,常见实现方法有主从同步复制和quorum复制等。 参考链接:http://blog.csdn.net/shlazww/article/details/38736511 2. consul的具体应用场景 docker、coreos 实例的注册与配置共享 vitess集群 SaaS应用的配置共享 与confd服务集成,动态生成nignx与haproxy配置文件 3. 优势 使用Raft算法保证一致性,比poxes算法更直接,zookeeper采用poxes算法。 Raft将过程分为leader election,log replication和commit(safety)三个阶段,每个server有leader,follower,candidate三种状态,正常时只有一个leader,其他为follower,server间通过RPC消息通信,follower不主动发起RPC,leader和candidate(选主时)主动发起。先选一个leader负责管理日志复制,leader接收log entries并复制给其他机器,决定何时将日志应用于状态机,leader可决定新entries位置,数据从leader流向其他机器,leader故障或失联会选举新leader。 参考链接:http://www.jdon.com/artichect/raft.html http://blog.csdn.net/cszhouwei/article/details/38374603 支持多数据中心,内外网服务用不同端口监听,避免单点故障,zookeeper等不支持多数据中心功能。 支持健康检查 提供web界面 支持http协议与dns协议接口 4. 安装(mac os x) 通过工具安装: brew cask install consul brew cask安装方便,参考链接:http://brew.sh/#install 5. 测试 与 运行consul 测试: consul 以服务端形式运行consul: consul agent -server -bootstrap-expect 1 -data-dir /tmp/consul 查看consul服务节点: consul members 将http请求发给consul server: $ curl localhost:8500/v1/catalog/nodes [{"Node":"Armons-MacBook-Air","Address":"10.1.10.38"}] 6. 注册服务 创建文件夹/etc/consul.d ,.d表示里面有许多配置文件。 将服务配置文件写入文件夹内,如: $ echo '{"service": {"name": "web", "tags": ["rails"], "port": 80}}' >/etc/consul.d/web.json 重启consul,并将配置文件的路径给consul: $ consul agent -server -bootstrap-expect 1 -data-dir /tmp/consul -config-dir /etc/consul.d 查询ip和端口: DNS方式: dig @127.0.0.1 -p 8600 web.service.consul SRV - **Http方式**: curl http://localhost:8500/v1/catalog/service/web 更新:通过http api能对service配置文件增删改查,更新完成后,可通过signup命令生效。 7. 组建集群 一个consul agent是独立程序,长时间运行的守护进程,运行在concul集群每个节点上。启动一个consul agent是孤立node,想知道集群其他节点需加入集群。 agent有server与client两种模式,server模式负责一致性工作,保证一致性和可用性(部分失败时),响应RPC,同步数据到其他节点代理;client模式与server通信,转发RPC到服务的代理agent,仅保存少量自身状态,轻量化、无状态。 agent除设置server/client模式、数据路径外,最好设置node的名称和ip。 LAN gossip pool包含同一局域网内所有节点(server与client),基本位于同一个数据中心DC;WAN gossip pool一般仅包含server,跨越多个DC数据中心,通过互联网或广域网通信。Leader服务器负责所有RPC请求查询并响应,其他服务器收到client的RPC请求会转发到leader服务器。 安装vagrant,初始化vagrant环境: sudo vagrant init 启动一个虚拟node节点: vagrant up 查看vm启动状态(包括vm名称): vagrant status 登陆到vm节点: vagrant ssh vm_name bootstrap模式下node可指定自己为leader,无需选举,然后依次启动其他server(非bootstrap模式),最后停止第一个server的bootstrap模式,重新以非bootstrap模式启动,server间自动选举leader。 分别在两个vm上配置consul agent,如: $ vagrant ssh n1 vagrant@n1:~$ consul agent -server -bootstrap-expect 1 \ -data-dir /tmp/consul -node=agent-one -bind=172.20.20.10 $ vagrant ssh n2 vagrant@n2:~$ consul agent -data-dir /tmp/consul -node=agent-two \ -bind=172.20.20.11 此时,应用consul members查询,两个consul node独立无关联。 将client加入到server集群中: vagrant@n1:~$ consul join 172.20.20.11 再用consul members查询,会发现多了一个node节点。 手动加入新节点麻烦,较好方法是将节点配置成自动加入集群: consul agent -atlas-join \ -atlas=ATLAS_USERNAME/infrastructure \ -atlas-token="YOUR_ATLAS_TOKEN" 离开集群: ctrl+c,或者 kill 指定的agent进程,就可以将相关的agent推出集群 让consul运行起来,consul server推荐3~5个,先启动一台server并配置到bootstrap模式,再依次启动其他server(非bootstrap模式),最后停止第一个server的bootstrap模式,重新以非bootstrap模式启动,server间自动选举leader。 参考链接:http://www.bubuko.com/infodetail-800623.html 8. 查询健康状态 应用http接口查询失败的节点: curl http://localhost:8500/v1/health/state/critical 对于失败的节点,应用DNS查询时无法拿到返回结果: dig @127.0.0.1 -p 8600 web.service.consul 9. K/V存储 查询所有K/V: curl -v http://localhost:8500/v1/kv/?recurse 保存键为web/key2, flags 为42, 值为true的记录: curl -X PUT -d 'test' http://localhost:8500/v1/kv/web/key2?flags=42 true 删除记录: curl -X DELETE http://localhost:8500/v1/kv/web/sub?recurse 更新值: curl -X PUT -d 'newval' http://localhost:8500/v1/kv/web/key1?cas=97 true 更新index: curl "http://localhost:8500/v1/kv/web/key2?index=101&wait=5s" 结果:[{"CreateIndex":98,"ModifyIndex":101,"Key":"web/key2","Flags":42,"Value":"dGVzdA=="}] 更详细的consul命令详解:http://m.oschina.net/blog/353392 10. 断电恢复outage recover 当有一台服务器不可用时,处理方法: 对服务器进恢复,然后重新上线 用新服务器,替代旧的consul服务器(这两种方式都需要将服务器ip与原来的ip相同) 添加新的服务器,ip无需与原来相同,步骤:停掉所有的consul服务器,将损坏的服务器ip从raft/peer.json中移除,重启其他服务器,并将新的服务器加入集群。 11. 其他 服务发现是怎么工作呢? 每一个服务发现工具都会提供一套API,使得组件可以用其来设置或搜索数据。正是如此,对于每一个组件,服务发现的地址要么强制编码到程序或容器内部,要么在运行时以参数形式提供。通常来说,发现服务用键值对形式实现,采用标准http协议交互。 服务发现门户的工作方式是:当每一个服务启动上线之后,他们通过发现工具来注册自身信息。它记录了一个相关组件若想使用某服务时的全部必要信息。例如,一个MySQL数据库服务会在这注册它运行的ip和端口,如有必要,登录时的用户名和密码也会留下。 当一个服务的消费者上线时,它能够在预设的终端查询该服务的相关信息。然后它就可以基于查到的信息与其需要的组件进行交互。负载均衡就是一个很好的例子,它可以通过查询服务发现得到各个后端节点承受的流量数,然后根据这个信息来调整配置。 这可将配置信息从容器内拿出。一个好处是可以让组件容器更加灵活,并不受限于特定的配置信息。另一个好处是使得组件与一个新的相关服务实例交互时变得简单,可以由管理工具动态进行调整配置。
-
随手记-为了保证实时一致需要使用强制事务 随手记-为了保证实时一致需要使用强制事务 事务相关原则 强制事务保证实时一致:为确保数据在任何时刻的一致性,对于一些关键场景需要使用强制事务来保障数据的实时准确性。 互联网强调最终一致:在互联网环境中,允许业务线在时间轴上的某个阶段数据和动作存在不一致情况,但最终必须保证数据的一致性。 第三方交互的消息机制:当与第三方系统进行交互时,务必采用消息机制作为中间层,以避免第三方系统的问题导致自身系统被拖垮。 消息中间件应用场景 大数据量请求扩展:主要用于减少系统中重要业务的压力,可处理大数据量请求。不过并非所有请求都适合用消息中间件异步处理,对于像ajax的主要业务且需要实时更新数据的情况,仍需采用同步方式。 特殊消息类型: 顺序消息:在一些业务场景中,如订单下单后通知出库信息,若消息顺序错误,可能导致报表统计数据不一致,所以需要保证消息顺序。同时存在后发消息先被消费的可能,因此要处理好顺序消息。 定时消息:按照设定的时间进行消息发送。 重复消息:当消费者未响应时,投递者会重复投递消息,例如气象系统通知消息。且要保证消息的幂等性,即无论消息投递多少次,都不会影响请求或数据的一致性,如订单通知始终只对应一条订单操作。 高并发场景:例如直播业务中更新粉丝数的操作,可利用消息中间件应对高并发情况。 消息中间件对比 RabbitMQ:其特点是放弃一定的吞吐量来保证数据一致性,当达到一定吞吐量时,可能需要进行特定的定制。 RocketMQ:目前已不再进行维护。 KafkaMQ:具有高吞吐量,但数据一致性表现不佳,存在数据丢失的风险。 DRDs(分布式关系型数据库服务) DRDs通过member_id来定位数据库,用于分布式数据库的管理和数据定位。 TXC(Taobao Transaction Construction) 数据库事务业务场景:由于单库存储在容量和性能上存在限制,TXC可用于解决分布式数据库事务相关问题,以满足业务需求。 分布式session处理:在分布式系统中,需要将session存放在redis中,以保证在不同节点间session的共享和一致性。 下订单业务示例 操作消耗差异:下订单操作中,insert操作消耗相对较低,而update操作消耗较高。在高并发情况下,为避免性能瓶颈,需要将update等操作进行异步化处理。 消息中间件与事务:消息中间件无法保证消息一定能发送成功,且本身不支持事务。但在分布式系统中,可通过半事务机制实现最终一致性。 半事务理解: 第一次理解:客户端以分布式、高并发的方式发送消息给消息中间件,而消费者(服务端)在消费消息时必须遵循事务规则(此理解可能存在错误)。 第二次理解:对于分布式事务,假设有两个存在先后顺序的事务,如事务1为消费10,事务2为增加10。通过消息中间件处理,事务1的消息发送给消息中间件后,消费者可消费事务1,但事务2必须在事务1执行完成后才能启动。 消费顺序:以双十一的下订单、付款、扣款流程为例,消费者必须按照事务的执行顺序,先消费下订单消息并提示用户下订单成功,接着处理付款消息并提示付款成功,最后进行扣款操作。按照这样的顺序逐步实现业务逻辑,以保证业务流程的正确和数据的一致性。
-
Lombok 安装、入门 - 消除冗长的java代码 Lombok 安装、入门 - 消除冗长的java代码 前言 逛开源社区的时候无意发现的,用了一段时间,觉得还可以,特此推荐一下。lombok提供了简单的注解的形式来帮助我们简化消除一些必须有但显得很臃肿的java代码。特别是相对于POJO,光说不做不是我的风格,先来看看吧。 lombok的官方网址:http://projectlombok.org/ lombok其实到这里我就介绍完了,开个玩笑,其实官网上有lombok三分四十九秒的视频讲解,里面讲的也很清楚了,而且还有文档可以参考。在这里我就不扯太多,先来看一下lombok的安装,其实这个官网视频上也有讲到啦 lombok安装 使用lombok是需要安装的,如果不安装,IDE则无法解析lombok注解。先在官网下载最新版本的JAR包,现在是0.11.2版本,我用的是0.11.0。第一次使用的时候我下载的是最新版本的,也就是我现在用的0.11.0,到现在已经更新了两个版本,更新的好快啊...... 1. 双击下载下来的JAR包安装lombok 我选择这种方式安装的时候提示没有发现任何IDE,所以我没安装成功,我是手动安装的。如果你想以这种方式安装,请参考官网的视频。 2. eclipse / myeclipse手动安装 将lombok.jar复制到myeclipse.ini / eclipse.ini所在的文件夹目录下 打开eclipse.ini / myeclipse.ini,在最后面插入以下两行并保存: -Xbootclasspath/a:lombok.jar -javaagent:lombok.jar 重启eclipse / myeclipse lombok注解 lombok提供的注解不多,可以参考官方视频的讲解和官方文档。 Lombok注解在线帮助文档:http://projectlombok.org/features/index. 下面介绍几个我常用的lombok注解: @Data:注解在类上;提供类所有属性的getting和setting方法,此外还提供了equals、canEqual、hashCode、toString方法 @Setter:注解在属性上;为属性提供setting方法 @Getter:注解在属性上;为属性提供getting方法 @Log4j:注解在类上;为类提供一个属性名为log的log4j日志对象 @NoArgsConstructor:注解在类上;为类提供一个无参的构造方法 @AllArgsConstructor:注解在类上;为类提供一个全参的构造方法 下面是简单示例 1. 不使用lombok的方案 public class Person { private String id; private String name; private String identity; private Logger log = Logger.getLogger(Person.class); public Person() { } public Person(String id, String name, String identity) { this.id = id; this.name = name; this.identity = identity; } public String getId() { return id; } public String getName() { return name; } public String getIdentity() { return identity; } public void setId(String id) { this.id = id; } public void setName(String name) { this.name = name; } public void setIdentity(String identity) { this.identity = identity; } } 2. 使用lombok的方案 @Data @Log4j @NoArgsConstructor @AllArgsConstructor public class Person { private String id; private String name; private String identity; } 上面的两个java类,从作用上来看,它们的效果是一样的,相比较之下,很明显,使用lombok要简洁许多,特别是在类的属性较多的情况下,同时也避免了修改字段名字时候忘记修改方法名所犯的低级错误。最后需要注意的是,在使用lombok注解的时候记得要导入lombok.jar包到工程。
-
ESLint 安装与命令选项说明 ESLint 安装与命令选项说明 安装步骤 安装 node.js 环境,可上网百度 执行 npm i -g eslint 命令安装 eslint 安装完成后执行 eslint -f junit -o D:\report.xml D:\test\code\dwzy\com.sgcc.pms.dwzy.bzzx\face ESLint 相关命令选项说明 1. -c 此选项允许你指定 ESLint 的替代配置文件(更多信息请参阅配置 ESLint)。默认情况下,ESLint 使用位于 conf/eslint.json 的自有配置文件。 示例: eslint -c ~/my-eslint.json file.js 该例子使用 ~/my-eslint.json 这个文件替代默认的配置文件。 2. --env 此选项启用特定环境。有关每个环境定义的全局变量的详细信息,请参阅配置文档。此标志仅启用环境,不会禁用其他配置文件中设置的环境。要指定多个环境,请使用逗号分隔它们,或多次使用该标志。 示例: eslint --env browser,node file.js eslint --env browser --env node file.js 3. --ext 此选项允许你指定 ESLint 在搜索 JavaScript 文件时将使用哪些文件扩展名。默认情况下,它仅使用 .js 作为文件扩展名。 示例: # 仅使用 .js2 扩展名 eslint --ext .js2 # 同时使用 .js 和 .js2 eslint --ext .js --ext .js2 # 也可同时使用 .js 和 .js2 eslint --ext .js,.js2 4. -f, --format 此选项指定控制台的输出格式。可能的格式有 "stylish"(默认)、"compact"、"checkstyle"、"jslint-xml"、"junit" 和 "tap"。 示例: eslint -f compact file.js 你还可以通过指定自定义格式化器文件的路径从命令行使用自定义格式化器。 示例: eslint -f ./customformat.js file.js 指定格式后,给定格式将输出到控制台。如果你想将输出保存到文件中,可以在命令行上这样做: eslint -f compact file.js > results.txt 这会将输出保存到 results.txt 文件中。 5. --global 此选项定义全局变量,使其不会被 no-undef 规则标记为未定义。全局变量默认为只读,但在变量名后附加 :true 可使其可写。要定义多个变量,请使用逗号分隔它们,或多次使用该标志。 示例: eslint --global require,exports:true file.js eslint --global require --global exports:true 6. -h, --help 此选项输出帮助菜单,显示所有可用选项。当存在此选项时,所有其他标志都将被忽略。 7. --ignore-path 此选项允许你指定用作 .eslintignore 的文件。默认情况下,ESLint 在当前工作目录中查找 .eslintignore。你可以通过提供不同文件的路径来覆盖此行为。 示例: eslint --ignore-path tmp/.eslintignore file.js 8. --no-color 禁用管道输出中的颜色。 示例: eslint --no-color file.js 9. --no-eslintrc 禁用使用 .eslintrc 和 package.json 文件中的配置。 示例: eslint --no-eslintrc file.js 10. --no-ignore 禁止从 .eslintignore 和 --ignore-path 文件中排除文件。 示例: eslint --no-ignore file.js 11. -o, --output-file 启用将报告写入文件。 示例: eslint -o ./test/test.xml 指定后,给定格式将输出到提供的文件名中。 12. --plugin 此选项指定要加载的插件。你可以省略插件名称中的前缀 eslint-plugin-。在使用插件之前,你必须使用 npm 安装它。 示例: eslint --plugin jquery file.js eslint --plugin eslint-plugin-mocha file.js 13. --quiet 此选项允许你禁用警告报告。如果启用此选项,ESLint 只报告错误。 示例: eslint --quiet file.js 14. --reset 此选项关闭 ESLint 默认配置文件(位于 conf/eslint.json)中启用的所有规则。ESLint 仍会报告语法错误。 示例: eslint --reset file.js 15. --rule 此选项指定要使用的规则。它们将合并到之前定义的任何规则中。要重新开始,只需与 --reset 标志组合使用。要定义多个规则,请使用逗号分隔它们,或多次使用该标志。使用 levn 格式来指定规则。如果规则在插件中定义,则必须在规则 ID 前加上插件名称和 /。 示例: eslint --rule 'quotes: [2, double]' eslint --rule 'guard-for-in: 2' --rule 'brace-style: [2, 1tbs]' eslint --rule 'jquery/dollar-sign: 2' 16. --rulesdir 此选项允许你指定第二个目录,从中加载规则文件。这允许你在运行时动态加载新规则。当你有不适合与 ESLint 捆绑在一起的自定义规则时,这很有用。 示例: eslint --rulesdir my-rules/ file.js 自定义规则目录中的规则必须遵循与捆绑规则相同的格式才能正常工作。你还可以通过包含多个 --rulesdir 标志来指定自定义规则的多个位置: eslint --rulesdir my-rules/ --rulesdir my-other-rules/ file.js 17. --stdin 此选项告诉 ESLint 从 STDIN 而不是文件读取和检查源代码。你可以使用它向 ESLint 传输代码。 示例: cat myfile.js | eslint --stdin 18. -v, --version 此选项将当前 ESLint 版本输出到控制台。存在此选项时,所有其他选项都将被忽略。