搜索到
88
篇与
的结果
-
 Angular2学习笔记 Angular2学习笔记 模板语法 模板是包在反引号 (`) 中的一个多行字符串。反引号 (`) ——注意,不是单引号 (') ——有很多好用的特性,比如允许多行字符串和模板字面量。 装饰器 @Component 装饰器,这个装饰器类(和我们随后将会学到的 @Directive 和 @Pipe 一样)是 InjectableMetadata 的子类型。实际上,这个 InjectableMetadata 装饰器是把一个类标识为依赖注入器实例化的目标。 TypeScript接口 接口只是 TypeScript 的一个设计期概念。JavaScript 没有接口。在生成 JavaScript 代码时,TypeScript 的接口就消失了。在运行期,没有接口类型信息可供 Angular 查找。 HTML Attribute 与 DOM Property Attribute 是由 HTML 定义的。Property 是由 DOM(Document Object Model) 定义的。 就算名字相同,HTML Attribute 和 DOM Property 也不是同一样东西。 组件交互 组件定义了一个 deleteRequest 属性,它是一个 EventEmitter 实例。(译注:deleteRequest 属性是导出 Output 属性,是组件与父级组件交互的主要方式之一。参见 输入和输出属性 和 父组件监听子组件的事件。我们需要用 @Output() 来装饰它,或者把它添加到组件元数据的 outputs 数组中,它才能在父级组件可见。) NgFor 与 trackBy 现在,把 NgForTrackBy 指令设置为那个追踪函数: <div *ngFor="let hero of heroes; trackBy:trackByHeroes">({{hero.id}}) {{hero.fullName}}</div> 追踪函数不会排除所有 DOM 更改。如果用来判断是否同一个英雄的属性变化了,Angular 就可能不得不更新 DOM 元素。但是如果这个属性没有变化——而且大多数时候它们不会变化——Angular 就能留下这些 DOM 元素。列表界面就会更加平滑,提供更好的响应。 安全导航操作符 Angular 的安全导航操作符 (?.) 是一种流畅而便利的方式,用来保护出现在属性路径中 null 和 undefined 值。这意味着,当 currentHero 为空时,保护视图渲染器,让它免于失败。 其他重要概念 数据绑定 Angular 支持多种数据绑定形式: 插值表达式:{{value}} 属性绑定:[property]="value" 事件绑定:(event)="handler()" 双向绑定:[(ngModel)]="property" 指令 Angular 有三种类型的指令: 组件:带有模板的指令 结构型指令:改变 DOM 布局的指令(如 *ngIf、*ngFor) 属性型指令:改变元素、组件或其他指令的外观和行为的指令(如 ngClass、ngStyle) 服务与依赖注入 Angular 服务是一个广义的概念,它包括应用所需的任何值、函数或特性。通常是一个具有明确用途的类。服务通过依赖注入系统被注入到需要它们的组件中。 模块 Angular 应用是模块化的,它拥有自己的模块系统,称作 NgModule。每个 Angular 应用都至少有一个 NgModule 类,也就是根模块,它习惯上命名为 AppModule,并位于一个名叫 app.module.ts 的文件中。
Angular2学习笔记 Angular2学习笔记 模板语法 模板是包在反引号 (`) 中的一个多行字符串。反引号 (`) ——注意,不是单引号 (') ——有很多好用的特性,比如允许多行字符串和模板字面量。 装饰器 @Component 装饰器,这个装饰器类(和我们随后将会学到的 @Directive 和 @Pipe 一样)是 InjectableMetadata 的子类型。实际上,这个 InjectableMetadata 装饰器是把一个类标识为依赖注入器实例化的目标。 TypeScript接口 接口只是 TypeScript 的一个设计期概念。JavaScript 没有接口。在生成 JavaScript 代码时,TypeScript 的接口就消失了。在运行期,没有接口类型信息可供 Angular 查找。 HTML Attribute 与 DOM Property Attribute 是由 HTML 定义的。Property 是由 DOM(Document Object Model) 定义的。 就算名字相同,HTML Attribute 和 DOM Property 也不是同一样东西。 组件交互 组件定义了一个 deleteRequest 属性,它是一个 EventEmitter 实例。(译注:deleteRequest 属性是导出 Output 属性,是组件与父级组件交互的主要方式之一。参见 输入和输出属性 和 父组件监听子组件的事件。我们需要用 @Output() 来装饰它,或者把它添加到组件元数据的 outputs 数组中,它才能在父级组件可见。) NgFor 与 trackBy 现在,把 NgForTrackBy 指令设置为那个追踪函数: <div *ngFor="let hero of heroes; trackBy:trackByHeroes">({{hero.id}}) {{hero.fullName}}</div> 追踪函数不会排除所有 DOM 更改。如果用来判断是否同一个英雄的属性变化了,Angular 就可能不得不更新 DOM 元素。但是如果这个属性没有变化——而且大多数时候它们不会变化——Angular 就能留下这些 DOM 元素。列表界面就会更加平滑,提供更好的响应。 安全导航操作符 Angular 的安全导航操作符 (?.) 是一种流畅而便利的方式,用来保护出现在属性路径中 null 和 undefined 值。这意味着,当 currentHero 为空时,保护视图渲染器,让它免于失败。 其他重要概念 数据绑定 Angular 支持多种数据绑定形式: 插值表达式:{{value}} 属性绑定:[property]="value" 事件绑定:(event)="handler()" 双向绑定:[(ngModel)]="property" 指令 Angular 有三种类型的指令: 组件:带有模板的指令 结构型指令:改变 DOM 布局的指令(如 *ngIf、*ngFor) 属性型指令:改变元素、组件或其他指令的外观和行为的指令(如 ngClass、ngStyle) 服务与依赖注入 Angular 服务是一个广义的概念,它包括应用所需的任何值、函数或特性。通常是一个具有明确用途的类。服务通过依赖注入系统被注入到需要它们的组件中。 模块 Angular 应用是模块化的,它拥有自己的模块系统,称作 NgModule。每个 Angular 应用都至少有一个 NgModule 类,也就是根模块,它习惯上命名为 AppModule,并位于一个名叫 app.module.ts 的文件中。 -
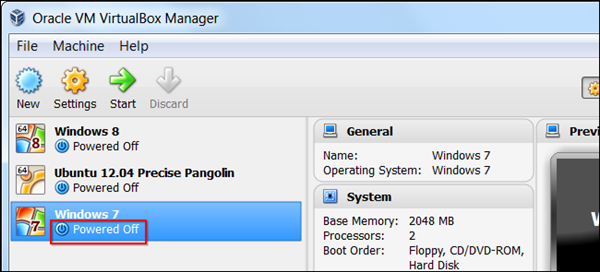
如何将Virtualbox和VMware虚拟机相互转换 如何将Virtualbox和VMware虚拟机相互转换 迁移到其他的虚拟机程序可行会吓倒一批人。如果你已经按照自己的喜好设置好了虚拟机,那么就不需要再从头安装——你可以迁移现有的虚拟机。 VirtualBox 和 VMware 使用不同的虚拟机格式,不过他们都支持标准的开放式虚拟化格式。将已经存在的虚拟机转换为 OVF/OVA 格式就可以导入其他的虚拟机程序。 不幸的是,这并不总是奏效。因为 VirtualBox 和 VMware 看起来使用些许不同的 OVA/OVF 实现方式,因此也不完全兼容。如果这不奏效,你可能需要重新安装虚拟机的客户机操作系统了。 VirtualBox 转换到 VMware 在迁移 Virtualbox(以下简称 Vbox —— 译者注) 虚拟机到 VMware 之前,确保在 Vbox 中虚拟机“已关闭”——而不是挂起。如果是挂起状态,启动虚拟机然后关掉它。 点击 Vbox 管理菜单,选择导出虚拟电脑。 选择要导出的虚拟机并选择文件保存位置。 Vbox 会创建一个开放式虚拟化格式包(OVA 文件)使得 VMware 可以导入。根据虚拟机磁盘文件的大小,此过程需稍等一段时间。 要将此 OVA 文件导入 VMware,点击打开虚拟机选项并找到你的 OVA 文件。 VirtualBox 和 VMware 不是完美兼容,所以你可能会看到一个警告信息,告诉你文件“不能通过OVF规格一致性验证”——不过如果你点击重试,可能会导入并成功运行虚拟机。 过程结束之后,你可以在在 VMware 中启动虚拟机,在虚拟机控制面板中卸载 Vbox 增强功能(VirtualBox Guest Additions),在虚拟机菜单中安装 VMware 工具。 VMware 转换到 VirtualBox 在将 VMware 虚拟机迁移到 Vbox 之前,确保在 VMware 的状态为“关闭电源” —— 非挂起。如果是挂起,启动虚拟机然后关机。 接下来,找到 OVFTool 所在目录。如果你用的是 VMware Player,目录在类似 C:\Program Files (x86)\VMware\VMware Player\OVFTool。按住 Shift 键,右击选择在此处打开命令行窗口。 按照下列语法运行 ovftool: ovftool source.vmx export.ovf 例如,如果我们转换位于 C:\Users\NAME\Documents\Virtual Machines\Windows 7 x64\Windows 7 x64.vmx 的虚拟机,并且创建 OVF 位于 C:\Users\NAME\export.ovf,我们需要执行下列命令: ovftool “C:\Users\NAME\Documents\Virtual Machines\Windows 7 x64\Windows 7 x64.vmx” C:\Users\NAME\export.ovf 如果提示“打开此盘失败”错误,很可能是虚拟机仍在运行或者没有正确关机——启动虚拟机并执行关机操作。 过程结束之后,可以使用管理菜单中的导入虚拟电脑选项,将 .ovf 文件导入 Vbox。 导入完成之后,你可以启动虚拟机,卸载 VMware 工具,并安装 Virtualbox 客户机增强工具。 文章来至
-
Docker给运行中的容器添加映射端口 Docker给运行中的容器添加映射端口 在Docker的使用场景中,有时需要为正在运行的容器添加映射端口,以便外部可以访问容器内的服务。以下为您介绍两种常见的方法: 方法1 1、获得容器IP 使用docker inspect命令来获取容器的详细信息,从中筛选出IP地址。在实际操作时,需要将container_name替换为您实际环境中的容器名,具体命令如下: docker inspect `container_name` | grep IPAddress 2、iptable转发端口 利用iptables工具进行端口转发设置,实现将容器的指定端口映射到Docker主机的另一个端口。例如,将容器的8000端口映射到Docker主机的8001端口,可使用以下命令: iptables -t nat -A DOCKER -p tcp --dport 8001 -j DNAT --to-destination 172.17.0.19:8000 在上述命令中,-t nat指定了使用nat表,用于网络地址转换;-A DOCKER表示在DOCKER链中添加一条规则;-p tcp指定协议为TCP;--dport 8001表明目标端口是8001;-j DNAT表示执行目的网络地址转换操作;--to-destination 172.17.0.19:8000则指定了要转换到的目标地址和端口,即容器的IP地址172.17.0.19和端口8000 。 方法2 1.提交一个运行中的容器为镜像 通过docker commit命令把正在运行的容器提交为一个新的镜像。其中,containerid为要提交的容器的ID,foo/live是自定义的镜像名称和标签,具体命令如下: docker commit containerid foo/live 2.运行镜像并添加端口 使用docker run命令来运行新创建的镜像,并通过-p参数指定端口映射关系。例如,将容器内部的80端口映射到主机的8000端口,命令如下: docker run -d -p 8000:80 foo/live /bin/bash 在该命令里,-d表示以守护进程模式在后台运行容器;-p 8000:80指定了端口映射,即把主机的8000端口映射到容器的80端口;foo/live是要运行的镜像名称;/bin/bash是容器启动时执行的命令,这里表示启动一个交互式的bash shell 。
-
使用nsenter进入Docker容器 使用nsenter进入Docker容器 Docker容器运行后,如何进入容器进行操作呢?起初我是用SSH。如果只启动一个容器,用SSH还能应付,只需要将容器的22端口映射到本机的一个端口即可。当我启动了五个容器后,每个容器默认是没有配置SSH Server的,安装配置SSHD,映射容器SSH端口,实在是麻烦。 我发现很多Docker镜像都是没有安装SSHD服务的,难道有其他方法进入Docker容器? 浏览了Docker的文档,我没有找到答案。还是要求助于无所不能的Google,万能的Google告诉我用nsenter吧。 在大多数Linux发行版中,util-linux包中含有nsenter.如果没有,你需要安装它. cd /tmp curl https://www.kernel.org/pub/linux/utils/util-linux/v2.24/util-linux-2.24.tar.gz \ | tar -zxf- cd util-linux-2.24 ./configure --without-ncurses make nsenter cp nsenter /usr/local/bin 使用shell脚本 docker-enter,将如下代码保存为docker-enter, chmod +x docker-enter #!/bin/sh if [ -e $(dirname "$0")/nsenter ]; then # with boot2docker, nsenter is not in the PATH but it is in the same folder NSENTER=$(dirname "$0")/nsenter else NSENTER=nsenter fi if [ -z "$1" ]; then echo "Usage: `basename "$0"` CONTAINER [COMMAND [ARG]...]" echo "" echo "Enters the Docker CONTAINER and executes the specified COMMAND." echo "If COMMAND is not specified, runs an interactive shell in CONTAINER." else PID=$(docker inspect --format "{{.State.Pid}}" "$1") if [ -z "$PID" ]; then exit 1 fi shift OPTS="--target $PID --mount --uts --ipc --net --pid --" if [ -z "$1" ]; then # No command given. # Use su to clear all host environment variables except for TERM, # initialize the environment variables HOME, SHELL, USER, LOGNAME, PATH, # and start a login shell. "$NSENTER" $OPTS su - root else # Use env to clear all host environment variables. "$NSENTER" $OPTS env --ignore-environment -- "$@" fi fi 运行 docker-enter <container id> ,这样就进入到指定的容器中 退出 exit
-
一致性算法--Raft 一致性算法--Raft 分布式一致性算法--Raft 前面一篇文章讲了Paxos协议,这篇文章讲它的姊妹篇Raft协议,相对于Paxos协议,Raft协议更为简单,也更容易工程实现。有关Raft协议和工程实现可以参考这个链接https://raft.github.io/,里面包含了大量的论文、视频以及动画演示,非常有助于理解协议。 概念与术语 leader:领导者,为客户提供服务(生成写日志)的节点,任何时候raft系统中只能有一个leader。 follower:跟随者,被动接受请求的节点,不会发送任何请求,只会响应来自leader或者candidate的请求。如果接受到客户请求,会转发给leader。 candidate:候选人,选举过程中产生,follower在超时时间内没有收到leader的心跳或者日志,则切换到candidate状态,进入选举流程。 termId:任期号,时间被划分成一个个任期,每次选举后都会产生一个新的termId,一个任期内只有一个leader。termId相当于paxos的proposalId。 RequestVote:请求投票,candidate在选举过程中发起,收到quorum(多数派)响应后,成为leader。 AppendEntries:附加日志,leader发送日志和心跳的机制。 election timeout:选举超时,如果follower在一段时间内没有收到任何消息(追加日志或者心跳),就是选举超时。 Raft协议主要包括三部分,leader选举,日志复制和成员变更。 Raft协议的原则和特点 a. 系统中有一个leader,所有的请求都交由leader处理,leader发起同步请求,当多数派响应后才返回客户端。 b. leader从来不修改自身的日志,只做追加操作。 c. 日志只从leader流向follower,leader中包含了所有已经提交的日志。 d. 如果日志在某个term中达成了多数派,则以后的任期中日志一定会存在。 e. 如果某个节点在某个(term, index)应用了日志,则在相同的位置,其它节点一定会应用相同的日志。 f. 不依赖各个节点物理时序保证一致性,通过逻辑递增的term - id和log - id保证。 e. 可用性:只要有大多数机器可运行并可相互通信,就可以保证可用,比如5节点的系统可以容忍2节点失效。 f. 容易理解:相对于Paxos协议实现逻辑清晰容易理解,并且有很多工程实现,而Paxos则难以理解,也没有工程实现。 g. 主要实现包括3部分:leader选举,日志复制,复制快照和成员变更;日志类型包括:选举投票,追加日志(心跳),复制快照。 leader选举流程 关键词:随机超时,FIFO 服务器启动时初始状态都是follower,如果在超时时间内没有收到leader发送的心跳包,则进入candidate状态进行选举,服务器启动时和leader挂掉时处理一样。为了避免选票瓜分的情况,比如5个节点ABCDE,leader A挂掉后,还剩4个节点,raft协议约定,每个服务器在一个term只能投一张票,假设B,D分别有最新的日志,且同时发起选举投票,则可能出现B和D分别得到2张票的情况,如果这样都得不到大多数确认,无法选出leader。为了避免这种情况发生,raft利用随机超时机制避免选票瓜分情况。选举超时时间从一个固定的区间随机选择,由于每个服务器的超时时间不同,则leader挂掉后,超时时间最短且拥有最多日志的follower最先开始选主,并成为leader。一旦candidate成为leader,就会向其他服务器发送心跳包阻止新一轮的选举开始。 发送日志信息:(term, candidateId, lastLogTerm, lastLogIndex) candidate流程: 在超时时间内没有收到leader的日志(包括心跳)。 将状态切换为candidate,自增currentTerm,设置超时时间。 向所有节点广播选举请求,等待响应,可能会有以下三种情况: (1). 如果收到多数派回应,则成为leader。 (2). 如果收到leader的心跳,且leader的term >= currentTerm,则自己切换为follower状态,否则,保持Candidate身份。 (3). 如果在超时时间内没有达成多数派,也没有收到leader心跳,则很可能选票被瓜分,则会自增currentTerm,进行新一轮的选举。 follower流程: 如果term < currentTerm,说明有更新的term,返回给candidate。 如果还没有投票,或者candidateId的日志(lastLogTerm, lastLogIndex)和本地日志一样或更新,则投票给它。 注意:一个term周期内,每个节点最多只能投一张票,按照先来先到原则。 日志复制流程 关键词:日志连续一致性,多数派,leader日志不变更 leader向follower发送日志时,会顺带邻近的前一条日志,follower接收日志时,会在相同任期号和索引位置找前一条日志,如果存在且匹配,则接收日志;否则拒绝,leader会减少日志索引位置并进行重试,直到某个位置与follower达成一致。然后follower删除索引后的所有日志,并追加leader发送的日志,一旦日志追加成功,则follower和leader的所有日志就保持一致。只有在多数派的follower都响应接受到日志后,表示事务可以提交,才能返回客户端提交成功。 发送日志信息:(term, leaderId, prevLogIndex, prevLogTerm, leaderCommitIndex) leader流程: 接收到client请求,本地持久化日志。 将日志发往各个节点。 如果达成多数派,再commit,返回给client。 备注: (1). 如果传递给follower的lastLogIndex >= nextIndex,则从nextIndex继续传递。 如果返回成功,则更新follower对应的nextIndex和matchIndex。 如果失败,则表示follower还差更多的日志,则递减nextIndex,重试。 (2). 如果存在N > commitIndex,且多数派matchIndex[i] >= N,且log[N].term == currentTerm,设置commitIndex = N。 follower处理流程: 比较term号和自身的currentTerm,如果term < currentTerm,则返回false。 如果(prevLogIndex, prevLogTerm)不存在,说明还差日志,返回false。 如果(prevLogIndex, prevLogTerm)与已有的日志冲突,则以leader为准,删除自身的日志。 将leader传过来的日志追加到末尾。 如果leaderCommitIndex > commitIndex,说明是新的提交位点,回放日志,设置commitIndex = min(leaderCommitIndex, index of last new entry)。 备注: 默认情况下,如果日志不匹配,会按logIndex逐条往前推进,直到找到match的位置,有一个简单的思路是,每次往前推进一个term,这样可以减少了网络交互,尽快早点match的位置,代价是可能传递了一些多余的日志。 快照流程 避免日志占满磁盘空间,需要定期对日志进行清理,在清理前需要做快照,这样新加入的节点可以通过快照 + 日志恢复。 快照属性: 最后一个已经提交的日志(termId,logIndex)。 新的快照生成后,可以删除之前的日志和以前的快照。 删日志不能太快,否则,crash后的机器,本来可以通过日志恢复,如果日志不存在,需要通过快照恢复,比较慢。 leader发送快照流程 传递参数(leaderTermId, lastIndex, lastTerm, offset, data[], done_flag) 如果发现日志落后太远(超过阀值),则触发发送快照流程。 备注: 快照不能太频繁,否则会导致磁盘IO压力较大;但也需要定期做,清理非必要的日志,缓解日志的空间压力,另外可以提高follower追赶的速度。 follower接收快照流程 如果leaderTermId < currentTerm,则返回。 如果是第一个块,创建快照。 在指定的偏移,将数据写入快照。 如果不是最后一块,等待更多的块。 接收完毕后,丢掉以前旧的快照。 删除掉不需要的日志。 集群配置变更 C(old):旧配置 C(new):新配置 C(old - new):过渡配置,需要同时在old和new中达成多数派才行 原则: 配置变更过程中,不会导致出现两个leader。 二阶段方案: 引入过渡阶段C(old - new) 约定: 任何一个follower在收到新的配置后,就采用新的配置确定多数派。 变更流程: leader收到从C(old)切换到C(new)配置的请求。 创建配置日志C(old - new),这条日志需要在C(old)和C(new)中同时达成多数派。 任何一个follower收到配置后,采用的C(old - new)来确定日志是否达成多数派(即使C(old - new)这条日志还没达成多数派)。 备注: 1,2,3阶段只有可能C(old)节点成为leader,因为C(old - new)没有可能成为多数派。 4. C(old - new)日志commit(达成多数派),则无论是C(old)还是C(new)都无法单独达成多数派,即不会存在两个leader。 5. 创建配置配置日志C(new),广播到所有节点。 6. 同样的,任何一个follower收到配置后,采用的C(new)来确定日志是否达成多数派。 备注: 在4,5,6阶段,只有可能含有C(old - new)配置的节点成为leader。 7. C(new)配置日志commit后,则C(old - new)无法再达成多数派。 8. 对于不在C(new)配置的节点,就可以退出了,变更完成。 备注: 在7,8阶段,只有可能含有C(new)配置成为leader。 所以整个过程中永远只会有一个leader。对于leader不在C(new)配置的情况,需要在C(new)日志提交后,自动关闭。 除了上述的两阶段方案,后续Raft作者又提出了一个相对简单的一阶段方案,每次只添加或者删除一个节点,这样设计不用引入过渡状态,这里不再赘述,有兴趣的同学可以去看他的毕业论文,我会附在后面的参考文档里面。 Q&A 1. Raft协议中是否存在“活锁”,如何解决? 活锁是相对死锁而言,所谓死锁,就是两个或多个线程相互锁等待,导致都无法推进的情况,而活锁则是多个工作线程(节点)都在运转,但是整体系统的状态无法推进,比如basic - paxos中某些情况下投票总是没有办法达成多数派。在Raft中,由于只要一阶段提交,选主过程中,可能出现多个节点同时发起选主的情况,这样导致选票瓜分,无法选出主,在下一轮选举中依旧如此,导致系统状态无法往前推进。Raft通过随机超时解决这个“活锁”问题。 2. Raft系统对于各个节点的物理时钟强一致有要求吗? Raft协议对物理时钟一致性没有要求,不需要通过原子钟NTP来校准时间,但是对于超时时间的设置有要求,具体规则如下: broadcastTime ≪ electionTimeout ≪ MTBF(Mean Time Between Failure) 首先,广播时间要远小于选举超时时间,leader通过广播不间断给follower发送心跳,如果这个时间比超时时间短,就会导致follower误以为leader挂了,触发选主;然后是超时时间要远小于机器的平均故障时间,如果MTBF比超时时间还短,则永远会发生选主问题,而在选主完成之前,无法对外正常提供服务,因此需要保证。一般broadcastTime可以认为是一个网络RTT,同城1ms以内,异地100ms以内,如果是跨国家,可能需要几百ms;而机器平均故障时间至少是以月为单位,因此选举超时时间需要设置1s到5s左右即可。 3. 如何保证leader上拥有了所有日志? 一方面,对于leader不变场景,日志只能从leader流向follower,并且发生冲突时以leader的日志为准;另一方面,对于leader一直有变换的场景,通过选举机制来保证,选举时采用(LogTerm, LogIndex)谁更新的比对方式,并且要得到多数派的认可,说明新leader的日志至少是多数派中最新的,另一方面,提交的日志一定也是达成了多数派,所以推断出leader有所有已提交的日志,不会漏。 4. Raft协议为什么需要日志连续性,日志连续性有有什么优势和劣势? 由Raft协议的选主过程可知,(termId, logId)一定在多数派中最新才可能成为leader,也就是说leader中一定已经包含了所有已经提交的日志。所以leader不需要从其它follower节点获取日志,保证了日志永远只从leader流向follower,简化了逻辑。但缺陷在于,任何一个follower在接受日志前,都需要接受之前的所有日志,并且只有追赶上了,才能有投票权利【否则,复制日志时,不考虑它们是大多数】,如果日志差的比较多,就会导致follower需要较长的时间追赶。任何一个没有追上最新日志的follower,没有投票权利,导致网络比较差的情况下,不容易达成多数派。而Paxos则允许日志有“空洞”,对网络抖动的容忍性更好,但处理“空洞”的逻辑比较复杂。 5. Raft如何保证日志连续性? leader向follower发送日志时,会顺带邻近的前一条日志,follower接受日志时,会在相同任期号和索引位置找前一条日志,如果存在且匹配,则接受日志,否则拒绝接受,leader会减少日志索引位置并进行重试,直到某个位置与follower达成一致。然后follower删除索引后的所有日志,并追加leader发送的日志,一旦日志追加成功,则follower和leader的所有日志就保持一致。而Paxos协议没有日志连续性要求,可以乱序确认。 6. 如果TermId小的先达成多数派,TermId大的怎么办?可能吗? 如果TermId小的达成了多数派,则说明TermId大的节点以前是leader,拥有最多的日志,但是没有达成多数派,因此它的日志可以被覆盖。但该节点会尝试继续投票,新leader发送日志给该节点,如果leader发现返回的termT > currentTerm,且还没有达成多数派,则重新变为follower,促使TermId更大的节点成为leader。但并不保证拥有较大termId的节点一定会成为leader,因为leader是优先判断是否达成多数派,如果已经达成多数派了,则继续为leader。 7. 达成多数派的日志就一定认为是提交的? 不一定,一定是在current_term内产生的日志,并且达成多数派才能认为是提交的,持久化的,不会变的。Raft中,leader保持原始日志的termId不变,任何一条日志,都有termId和logIndex属性。在leader频繁变更的情况下,有可能出现某条日志在某种状态下达成了多数派,但日志最终可能被覆盖掉,比如: (a). S1是leader,termId是2,写了一条日志到S1和S2,(termId,logIndex)为(2, 2) (b). S1 crash,S5利用S3,S4,S5当选leader,自增termId为3,本地写入一条日志,(termId,logIndex)为(3, 2) (c). S5 crash,S1重启后重新当选leader,自增termId为4,将(2, 2)重新复制到多数派,提交前crash (d). S1 crash,S5利用S2,S3,S4当选leader,则将(3, 2)的日志重新复制到多数派,并提交,这样(2, 2)这条日志曾经虽然达成多数派也会被覆盖。 (e). 假设S1在第一个任期内,将(2, 2)达成多数派,则后面S3不会成为leader,也就不会出现覆盖的情况。 参考文档 https://raft.github.io/raft.pdf https://ramcloud.stanford.edu/~ongaro/thesis.pdf https://ramcloud.stanford.edu/~ongaro/userstudy/paxos.pdf