搜索到
88
篇与
的结果
-
 AngularJS angular.identity 和 angular.noop AngularJS angular.identity 和 angular.noop angular.identity 函数返回本身的第一个参数。这个函数一般用于函数风格。 格式: angular.identity() 示例代码: (function () { angular.module("Demo", []) .controller("testCtrl", testCtrl); function testCtrl() { var getResult = function (fn, val) { return (fn || angular.identity)(val); }; var result = getResult(function (n) { return n * 2; }, 3); // result = 6 var null_result = getResult(null, 3);// null_result = 3 var undefined_result = getResult(undefined, 3);// undefined_result = 3 }; }()) angular.noop 一个不执行任何操作的空函数。这个函数一般用于函数风格。 格式: angular.noop(); 示例代码: (function () { angular.module("Demo", []) .controller("testCtrl", testCtrl); function testCtrl() { var _console = function (v) { return v * 2; }; var getResult = function (fn, val) { return (fn || angular.noop)(val); }; var firstResult = getResult(_console, 3);//6 var secondResult = getResult(null, 3);//undefined var thirdResult = getResult(undefined, 3);// undefined }; }()) 总结 这两个API的用途有点特殊。总的来说,这两个方法都是用来编写函数时使用的,根据上面示例代码及运行结果可以看出,它们的作用是用来防止函数传入的参数是null或undefined或其他不能操作的对象。 如果不使用这两个函数,当你在函数调用时传入null/undefined/或者其他不能执行的对象,控制台会直接报错。 angular.identity:当传入null/undefined时,返回传入的第二个参数值 angular.noop:当传入null/undefined时,返回undefined
AngularJS angular.identity 和 angular.noop AngularJS angular.identity 和 angular.noop angular.identity 函数返回本身的第一个参数。这个函数一般用于函数风格。 格式: angular.identity() 示例代码: (function () { angular.module("Demo", []) .controller("testCtrl", testCtrl); function testCtrl() { var getResult = function (fn, val) { return (fn || angular.identity)(val); }; var result = getResult(function (n) { return n * 2; }, 3); // result = 6 var null_result = getResult(null, 3);// null_result = 3 var undefined_result = getResult(undefined, 3);// undefined_result = 3 }; }()) angular.noop 一个不执行任何操作的空函数。这个函数一般用于函数风格。 格式: angular.noop(); 示例代码: (function () { angular.module("Demo", []) .controller("testCtrl", testCtrl); function testCtrl() { var _console = function (v) { return v * 2; }; var getResult = function (fn, val) { return (fn || angular.noop)(val); }; var firstResult = getResult(_console, 3);//6 var secondResult = getResult(null, 3);//undefined var thirdResult = getResult(undefined, 3);// undefined }; }()) 总结 这两个API的用途有点特殊。总的来说,这两个方法都是用来编写函数时使用的,根据上面示例代码及运行结果可以看出,它们的作用是用来防止函数传入的参数是null或undefined或其他不能操作的对象。 如果不使用这两个函数,当你在函数调用时传入null/undefined/或者其他不能执行的对象,控制台会直接报错。 angular.identity:当传入null/undefined时,返回传入的第二个参数值 angular.noop:当传入null/undefined时,返回undefined -
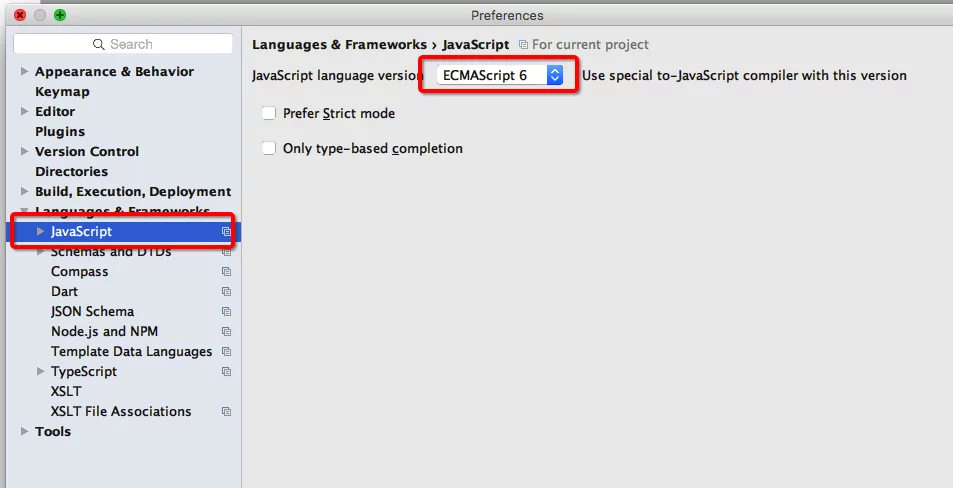
在 WebStorm 下断点调试 在 WebStorm 下断点调试 配置 WebStorm 将新建的 ThinkJS 2015+ 项目导入到 WebStorm 中,然后在首选项的 JavaScript 版本设置为 ECMASCRIPT 6。如: 点击右上角的 Edit Configurations,然后新建个项目,项目类型选择 Node.js。如: 在右侧配置项 JavaScript File 里填入 www/development.js,或者通过右侧的按钮选择也可以。如: 调试 点击右上角的调试按钮,会启动 Node.js 服务。如: 如果之前已经在命令行下启动了服务,需要关掉,否则会出现端口被占用导致报错的情况。 在 app/ 目录下的文件设置断点(一定要在 app/ 目录下,不能是 src/ 目录下),如: 打开浏览器,访问对应的接口。返回 WebStorm,点击调试按钮就可以进行调试了,并且看到的是源代码。
-
Phabricator系列之国际化-中文 Phabricator系列之国际化-中文 Phabricator现在有新的方式进行国际化(主要是中文化)了. (2015-07-06) 前一段时间, 团队用的Phabricator开始滚动往前更新, 确定下来是每周和官方网站同步一次. 之前也是为了解决一个问题, 在任务(Maniphest)分配的时候选择成员的时候, 少了一个成员, 只能用(Edit Task)重新指派人. 后来无意间发现一个清除缓存的命令, 一执行就修复好了. ./bin/cache purge 当前本文的重点在于中文化, 参考了现在最新的wiki, 发现现在的中文化比以前方便许多, 不用再每次同步都要还原几个文件再辛苦执行arc liberate 第一步, 我们新建一个PhutilCNChineseLocale.php, 里面放一个PhutilCNChineseLocale继承一个类叫做PhutilLocale, 实现getLocaleCode和getLocaleName这两个方法 分别在这两个方法里面返回zh_CN和中文 (简体中文) 第二步, 新建PhabricatorCNChineseTranslation.php, 继承PhutilTranslation类, 实现getLocaleCode和getTranslations这两个方法 getLocaleCode中返回zh_CN, getTranslations中返回一个数组, 这个数组还是用我们之前生成的数据 ./bin/i18n extract ./src/applications/ 执行完成之后会生成我们所需要的数组, 把这个数据放到getTranslations里面. (这个数据还是超大的, 我这里大概1.6M的样子, 因为Phabricator几十个应用都有了) 如果只用到某些应用的话, 也可以只生成部分 ./bin/i18n extract ./src/applications/maniphest/ 第三步, 一点一点把getTranslations里面的数组翻译过来, 把值为null的都翻译成中文就可以. 第四步, 我们进入个人设置页面, 把Translation这一项, 选择下拉框里面的中文(简体中文), 保存设置就能看到中文结果了. 最后完成的时候, 就是这样一个目录结构 ├── phabricator-zh_CN │ ├── PhabricatorCNChineseTranslation.php │ ├── PhutilCNChineseLocale.php 这里给出我们项目中的一个结构, 直接将这个clone到本地phabricator/src/extensions目录下面就可以了 https://github.com/wanthings/phabricator-zh_CN.git 本文都内容都是参考官方wiki写的, 以下都是参考文章 Adding New Classes Internationalization
-
Angular.js中指令compile与link原理剖析 AngularJS中的Compile与Link 在AngularJS中,当我们设置了link选项时,实际上是创建了一个postLink()链接函数,以便compile()函数可以定义这个链接函数。 编译(compile)和链接(link)的职责 编译(compile) 函数负责对模板DOM进行转换。 链接(link) 函数负责将作用域(Scope)和DOM进行链接。 Compile与Link的区别 Compile函数 对指令的模板进行转换。 Link函数 在模型(Model)和视图(View)之间建立关联,并包括在元素上注册事件监听。 作用域(Scope)在链接阶段才会被绑定到元素上,因此在compile阶段操作scope会报错。 对于同一个指令的多个实例,compile只会执行一次;而link对于指令的每个实例都会执行一次。 在一般情况下,我们只需要编写link函数即可。 如果你自定义了compile函数,那么自定义的link函数将会无效,因为compile函数应该返回一个link函数供后续处理。 示例代码 // require 'SomeController' link: function(scope, element, attrs, SomeController) { // 在这里操作DOM,可以访问required指定的控制器 }
-
随笔-第一次接触DDD与微服务 随笔-第一次接触DDD与微服务 首先,感谢公司提供这次学习DDD(领域驱动设计)的机会。 经过上次雷老师的讲解,这两个月来,我对微服务架构有了整体的了解,并持续关注了雷老师的项目。结合这次培训和个人理解,我总结了以下几点: 微服务架构的核心要素 微服务架构主要包括: 基础设施(原中间件):Redis(缓存管理)、Kafka(消息队列)、Consul/Eureka(服务注册)、Elasticsearch(搜索引擎)等。 DDD(领域驱动设计):重点在于领域建模和界限上下文的划分。 数据库:微服务架构下的数据管理策略,包括分库分表、分布式事务等。 Docker:环境容器化,让环境像代码一样可定义、可声明,提升部署效率。 其中,对我来说最陌生但最重要的部分是基础设施,这次培训重点讲解了如何将基础设施与DDD整合,并提供了基本的DEMO示例。 领域驱动设计(DDD)理解 传统软件设计通常围绕数据库进行架构,而DDD则是围绕领域和界限上下文进行业务扩展。 领域及子域 以我们公司所处的服装行业为例,面料平台就是一个领域,而它可以进一步拆分为多个子域: 交易中心(核心域) 运营中心 商家管理 扫描仪 不同子域之间存在层级关系,例如:交易中心与商家管理之间是上下级关系。 界限上下文 以交易平台为例,它的界限上下文包括: 面料管理(面料列表、搜索、详情) 面料对比(加入对比、对比分析、取消对比) 用户管理(个人用户) 实体、值对象、聚合 实体:具有唯一标识,例如“用户”。 值对象:数据不可变、无唯一标识,例如“用户地址”。 聚合:封装了实体、值对象和仓储,并通过服务暴露出去。 工厂模式 工厂用于创建和管理复杂对象,确保领域对象的一致性。 DDD 与微服务的整合 在微服务架构中,Spring Cloud 通过封装 Redis、Kafka、Consul 等基础设施,使其能够以注解和配置的方式无缝集成项目。这些组件如同武器,而DDD是一个武林高手,关键在于如何合理运用。 此外,Spring Boot 通过注解取代 XML 配置,实现“约定优于配置”,简化开发流程,符合当前行业趋势。 微服务架构落地的关键问题 1. 服务化后的管理 JAR 包如何管理?是每个包一个 Docker 镜像,还是一个界限上下文一个镜像? 端口、日志等规范化管理。 2. Docker 仓库管理 如何高效存储和管理微服务镜像,减少重复构建和拉取。 3. 安全性 可以采用 OAuth + Shiro 结合 Zuul 路由 来控制权限。 4. CI/CD(持续集成 & 持续部署) 如何使用 Jenkins 实现自动化部署,减少人工干预,提高效率。 5. 版本号管理 采用 Maven + Git 进行版本控制,避免人工打版本号。 JAR 包管理策略,避免版本混乱。 6. 单体架构向微服务迁移的思考 为什么要迁移?微服务是否适合当前企业需求? 迁移前的技术债偿还、新架构设计原则、团队变革等准备工作。 迁移过程中需要遵循的设计规范。 分布式事务一致性:虽然雷老师建议使用 TSDB 而非传统事务,但目前对其原理仍有疑问,需要进一步研究。 中间件选型:如何选择合适的消息队列、数据库、缓存方案等。 如何让其他职能团队平滑切入?(UI、产品、运维、测试、前端等) 结语 微服务架构的落地涉及众多技术和管理挑战,这次培训让我对DDD有了更深入的理解,同时也意识到微服务架构实施过程中仍有许多待解决的问题,需要进一步探索和实践。 雷老师的github地址:https://github.com/linux-china