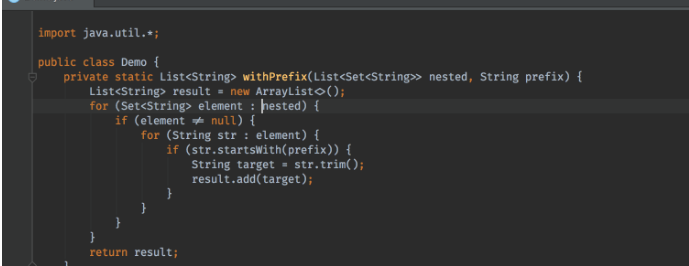
搜索到
88
篇与
的结果
-
 Docker Compose学习笔记 Docker Compose学习笔记 如果需要指定额外的编译镜像的 Dockefile 文件,可以通过该指令来指定。 例如 dockerfile: Dockerfile-alternate 注意,该指令不能跟 image 同时使用,否则 Compose 将不知道根据哪个指令来生成最终的服务镜像。 extends 基于其它模板文件进行扩展。 例如我们已经有了一个 webapp 服务,定义一个基础模板文件为 common.yml。 # common.yml webapp: build: ./webapp environment: - DEBUG=false - SEND_EMAILS=false 再编写一个新的 development.yml 文件,使用 common.yml 中的 webapp 服务进行扩展。 # development.yml web: extends: file: common.yml service: webapp ports: - "8000:8000" links: - db environment: - DEBUG=true db: image: postgres 使用 extends 需要注意: 要避免出现循环依赖,例如 A 依赖 B,B 依赖 C,C 反过来依赖 A 的情况。 extends 不会继承 links 和 volumes_from 中定义的容器和数据卷资源。
Docker Compose学习笔记 Docker Compose学习笔记 如果需要指定额外的编译镜像的 Dockefile 文件,可以通过该指令来指定。 例如 dockerfile: Dockerfile-alternate 注意,该指令不能跟 image 同时使用,否则 Compose 将不知道根据哪个指令来生成最终的服务镜像。 extends 基于其它模板文件进行扩展。 例如我们已经有了一个 webapp 服务,定义一个基础模板文件为 common.yml。 # common.yml webapp: build: ./webapp environment: - DEBUG=false - SEND_EMAILS=false 再编写一个新的 development.yml 文件,使用 common.yml 中的 webapp 服务进行扩展。 # development.yml web: extends: file: common.yml service: webapp ports: - "8000:8000" links: - db environment: - DEBUG=true db: image: postgres 使用 extends 需要注意: 要避免出现循环依赖,例如 A 依赖 B,B 依赖 C,C 反过来依赖 A 的情况。 extends 不会继承 links 和 volumes_from 中定义的容器和数据卷资源。 -
如何用 Docker 构建、运行、发布来一个 spring Boot 应用 如何用 Docker 构建、运行、发布来一个 spring Boot 应用。 Docker 简介 Docker 是一个 Linux 容器管理工具包,具备“社交”方面,允许用户发布容器的 image (镜像),并使用别人发布的 image。Docker image 是用于运行容器化进程的方案,在本文中,我们将构建一个简单的 Spring Boot 应用程序。 有关 Docker 的详细介绍,可以移步至 《简述 Docker》 前置条件 JDK 1.8+ Maven 3.0+ Docker 最新版。有关 Docker 在的安装,可以参阅 《Docker 在 CentOS 下的安装、使用》。 如果你的电脑不是 Linux 系统,最好装个虚拟机,在虚拟机里面装个 Linux ,因为 Docker 的依赖 Linux。 用 Maven 构建项目 创建目录结构 项目的目录结构因符合 Maven 的约定。 在 *nix 系统下执行 mkdir -p src/main/Java/docker_spring_boot ,生产如下结构 : └── src └── main └── java └── com └── lzh └── docker_spring_boot 创建 pom.xml 文件 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.lzh</groupId> <artifactId>docker-spring-boot</artifactId> <packaging>jar</packaging> <version>1.0.0</version> <name>docker-spring-boot</name> <description>Getting started with Spring Boot and Docker</description> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.3.3.RELEASE</version> <relativePath/> </parent> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> <!-- tag::plugin[] --> <plugin> <groupId>com.spotify</groupId> <artifactId>docker-maven-plugin</artifactId> <version>0.4.3</version> <configuration> <imageName>${docker.image.prefix}/${project.artifactId}</imageName> <dockerDirectory>src/main/docker</dockerDirectory> <resources> <resource> <targetPath>/</targetPath> <directory>${project.build.directory}</directory> <include>${project.build.finalName}.jar</include> </resource> </resources> </configuration> </plugin> <!-- end::plugin[] --> </plugins> </build> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <docker.image.prefix>lzh</docker.image.prefix> <spring.boot.version>1.3.3.RELEASE</spring.boot.version> </properties> </project> Spring Boot Maven plugin 提供了很多方便的功能: 它收集的类路径上所有 jar 文件,并构建成一个单一的、可运行的“über-jar”,这使得它更方便地执行和传输服务。 它搜索的 public static void main() 方法来标记为可运行的类。 它提供了一个内置的依赖解析器,用于设置版本号以匹配 Spring Boot 的依赖。您可以覆盖任何你想要的版本,但它会默认选择的 Boot 的版本集。 Spotify 的 docker-maven-plugin 插件是用于构建 Maven 的 Docker Image imageName指定了镜像的名字,本例为 lzh/docker-spring-boot dockerDirectory指定 Dockerfile 的位置 resources是指那些需要和 Dockerfile 放在一起,在构建镜像时使用的文件,一般应用 jar 包需要纳入。本例,只需一个 jar 文件。 编写 Spring Boot 应用 编写一个简单的 Spring Boot 应用 : src/main/java/com/lzh/docker_spring_boot/Application.java: package com.lzh.docker_spring_boot; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; /** * 主应用入口 * @author lzh * @date 2017年3月19日 */ @SpringBootApplication @RestController public class Application { @RequestMapping("/") public String home() { return "Hello Docker World." + "<br />Welcome to SpringBoot</li>"; } public static void main(String[] args) { SpringApplication.run(Application.class, args); } } 解释下上面的代码: 类用 @SpringBootApplication @RestController 标识,可用 Spring MVC 来处理 Web 请求。 @RequestMapping 将 / 映射到 home() ,并将”Hello Docker World” 文本作为响应。 main() 方法使用 Spring Boot 的 SpringApplication.run() 方法来启动应用。 运行程序 使用 Maven 编译: mvn package 运行: java -jar target/docker-spring-boot-1.0.0.jar 访问项目 如果程序正确运行,浏览器访问 http://localhost:8080/,可以看到页面 “Hello Docker World.” 字样。 将项目容器化 Docker 使用 Dockerfile 文件格式来指定 image 层, 创建文件 src/main/docker/Dockerfile: FROM frolvlad/alpine-oraclejdk8:slim VOLUME /tmp ADD docker-spring-boot-1.0.0.jar app.jar ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"] 解释下这个配置文件: VOLUME 指定了临时文件目录为/tmp。其效果是在主机 /var/lib/docker 目录下创建了一个临时文件,并链接到容器的/tmp。改步骤是可选的,如果涉及到文件系统的应用就很有必要了。/tmp目录用来持久化到 Docker 数据文件夹,因为 Spring Boot 使用的内嵌 Tomcat 容器默认使用/tmp作为工作目录 项目的 jar 文件作为 “app.jar” 添加到容器的 ENTRYPOINT 执行项目 app.jar。为了缩短 Tomcat 启动时间,添加一个系统属性指向 “/dev/urandom” 作为 Entropy Source 构建 Docker Image 执行构建成为 docker image: mvn package docker:build 运行 运行 Docker Image docker run -p 8080:8080 -t lzh/docker-spring-boot [root@lzh spring-boot]# docker run -p 8080:8080 -t lzh/docker-spring-boot . ____ _ __ _ _ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | ) ) ) ) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v1.3.3.RELEASE) 2016-03-20 08:45:51.276 INFO 1 --- [ main] c.lzh.docker_spring_boot.Application : Starting Application v1.0.0 on 048fb623038f with PID 1 (/app.jar started by root in /) 2016-03-20 08:45:51.289 INFO 1 --- [ main] c.lzh.docker_spring_boot.Application : No active profile set, falling back to default profiles: default 2016-03-20 08:45:51.722 INFO 1 --- [ main] ationConfigEmbeddedWebApplicationContext : Refreshing org.springframework.boot.context.embedded.AnnotationConfigEmbeddedWebApplicationContext@669af5fc: startup date [Sun Mar 20 08:45:51 GMT 2016]; root of context hierarchy 2016-03-20 08:45:54.874 INFO 1 --- [ main] o.s.b.f.s.DefaultListableBeanFactory : Overriding bean definition for bean 'beanNameViewResolver' with a different definition: replacing [Root bean: class [null]; scope=; abstract=false; lazyInit=false; autowireMode=3; dependencyCheck=0; autowireCandidate=true; primary=false; factoryBeanName=org.springframework.boot.autoconfigure.web.ErrorMvcAutoConfiguration$WhitelabelErrorViewConfiguration; factoryMethodName=beanNameViewResolver; initMethodName=null; destroyMethodName=(inferred); defined in class path resource [org/springframework/boot/autoconfigure/web/ErrorMvcAutoConfiguration$WhitelabelErrorViewConfiguration.class]] with [Root bean: class [null]; scope=; abstract=false; lazyInit=false; autowireMode=3; dependencyCheck=0; autowireCandidate=true; primary=false; factoryBeanName=org.springframework.boot.autoconfigure.web.WebMvcAutoConfiguration$WebMvcAutoConfigurationAdapter; factoryMethodName=beanNameViewResolver; initMethodName=null; destroyMethodName=(inferred); defined in class path resource [org/springframework/boot/autoconfigure/web/WebMvcAutoConfiguration$WebMvcAutoConfigurationAdapter.class]] 2016-03-20 08:45:57.893 INFO 1 --- [ main] s.b.c.e.t.TomcatEmbeddedServletContainer : Tomcat initialized with port(s): 8080 (http) 2016-03-20 08:45:57.982 INFO 1 --- [ main] o.apache.catalina.core.StandardService : Starting service Tomcat 2016-03-20 08:45:57.984 INFO 1 --- [ main] org.apache.catalina.core.StandardEngine : Starting Servlet Engine: Apache Tomcat/8.0.32 2016-03-20 08:45:58.473 INFO 1 --- [ost-startStop-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext 2016-03-20 08:45:58.473 INFO 1 --- [ost-startStop-1] o.s.web.context.ContextLoader : Root WebApplicationContext: initialization completed in 6877 ms 2016-03-20 08:45:59.672 INFO 1 --- [ost-startStop-1] o.s.b.c.e.ServletRegistrationBean : Mapping servlet: 'dispatcherServlet' to [/] 2016-03-20 08:45:59.695 INFO 1 --- [ost-startStop-1] o.s.b.c.embedded.FilterRegistrationBean : Mapping filter: 'characterEncodingFilter' to: [/*] 2016-03-20 08:45:59.701 INFO 1 --- [ost-startStop-1] o.s.b.c.embedded.FilterRegistrationBean : Mapping filter: 'hiddenHttpMethodFilter' to: [/*] 2016-03-20 08:45:59.703 INFO 1 --- [ost-startStop-1] o.s.b.c.embedded.FilterRegistrationBean : Mapping filter: 'httpPutFormContentFilter' to: [/*] 2016-03-20 08:45:59.703 INFO 1 --- [ost-startStop-1] o.s.b.c.embedded.FilterRegistrationBean : Mapping filter:'requestContextFilter' to: [/*] 2016-03-20 08:46:00.862 INFO 1 --- [ main] s.w.s.m.m.a.RequestMappingHandlerAdapter : Looking for @ControllerAdvice: org.springframework.boot.context.embedded.AnnotationConfigEmbeddedWebApplicationContext@669af5fc: startup date [Sun Mar 20 08:45:51 GMT 2016]; root of context hierarchy 2016-03-20 08:46:01.166 INFO 1 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/]}" onto public java.lang.String com.lzh.docker_spring_boot.Application.home() 2016-03-20 08:46:01.189 INFO 1 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/error],produces=[text/html]}" onto public org.springframework.web.servlet.ModelAndView org.springframework.boot.autoconfigure.web.BasicErrorController.errorHtml(javax.servlet.http.HttpServletRequest,javax.servlet.http.HttpServletResponse) 2016-03-20 08:46:01.190 INFO 1 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/error]}" onto public org.springframework.http.ResponseEntity<java.util.Map<java.lang.String, java.lang.Object>> org.springframework.boot.autoconfigure.web.BasicErrorController.error(javax.servlet.http.HttpServletRequest) 2016-03-20 08:46:01.302 INFO 1 --- [ main] o.s.w.s.handler.SimpleUrlHandlerMapping : Mapped URL path [/webjars/**] onto handler of type [class org.springframework.web.servlet.resource.ResourceHttpRequestHandler] 2016-03-20 08:46:01.302 INFO 1 --- [ main] o.s.w.s.handler.SimpleUrlHandlerMapping : Mapped URL path [/**] onto handler of type [class org.springframework.web.servlet.resource.ResourceHttpRequestHandler] 2016-03-20 08:46:01.438 INFO 1 --- [ main] o.s.w.s.handler.SimpleUrlHandlerMapping : Mapped URL path [/**/favicon.ico] onto handler of type [class org.springframework.web.servlet.resource.ResourceHttpRequestHandler] 2016-03-20 08:46:01.833 INFO 1 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Registering beans for JMX exposure on startup 2016-03-20 08:46:02.332 INFO 1 --- [ main] s.b.c.e.t.TomcatEmbeddedServletContainer : Tomcat started on port(s): 8080 (http) 2016-03-20 08:46:02.343 INFO 1 --- [ main] c.lzh.docker_spring_boot.Application : Started Application in 13.194 seconds (JVM running for 15.828) 推送 image 到 Docker Hub 首先,你在 Docker Hub 要有注册账号,且创建了相应的库; 其次,docker 推送前,先要登录,否则报unauthorized: access to the requested resource is not authorized的错误 执行: docker login [root@lzhspring-boot]# docker login Username: root Password: Email: idinu@gmail.com WARNING: login credentials saved in /root/.docker/config.json Login Succeeded - 执行推送 docker push lzh/docker-spring-boot [root@lzhspring-boot]# docker push lzh/docker-spring-boot The push refers to a repository [docker.io/lzh/docker-spring-boot] 751d29eef02e: Layer already exists 4da3741f39c7: Pushed 5f70bf18a086: Layer already exists 7e4d0cb13643: Layer already exists 8f045733649f: Layer already exists latest: digest: sha256:eb4d5308ba1bb27489d808279e74784bda6761b3
-
Java8阅读笔记 懂得什么是行为参数化 http://www.tuicool.com/articles/yIv2Mjy 对比: 通过IntelliJ IDEA 2016.3 来更好使用Java 8的Stream API 归约 使用归约方法的有事和并行化: 相比于前面写的逐步迭代求和,使用reduce的好处在于,这里的迭代被内部迭代抽象掉了,这让内部实现得以选择并行执行reduce操作。而迭代式求和例子要更新共享变量sum,这不是那么容易并行化的。如果你加入了同步,很可能会发现线程竞争抵消了并行本应带来的性能提升! java8 策略模式重构:P192 例子:对输入的内容进行验证或者格式化(比如只包含小写字母或者数字)。 // 此接口实际是一个函数接口 public interface ValidationStrategy { boolean execute(String s); } // 两个实现类 public class IsAllLowerCase implements ValidationStrategy { public boolean execute(String s) { return s.matches("[a-z] +"); } } public class IsNumeric implements ValidationStrategy { public boolean execute(String s) { return s.matches("\\d+""); } } / / 定义一个类去使用 public class Validator{ private final ValidationStrategy strategy; public Validator(ValidationStrategy v){ this.strategy = v; } public boolean validate(String s){ return strategy.execute(s); } } // 实际业务中使用 Validator numericValidateor = new Validator(new IsNumeric()); boolean b1 = numericValidator.validate("aaaa"); Validator lowerCaseValidator = new Validator(new IsAllLowerCase()); boolean b2 = lowerCaseValidator.validate("bbbb"); 使用Lambda表达式: 不需要编写两个实现类直接使用Lambda表达式: Validator numericValidator = new Validator((String s) -> s.matches("[a-z]+")); boolean b1 = numericValidaor.validate("aaaa"); Validator lowerCaseValidator = new Validator((String s) -> s.matches("\\d+")); boolean b2 = lowerCaseValidator.validate("bbbb"); 引入Optional类的意图并非消除每一个null引用。 创建Optional对象 1.声明一个空的Optional Optional<Car> optCar = Optional.empty(); 2.依据一个非空值创建Optional Optional<Car> optCar = Optional.of(car);// 如果car是一个null,这段代码会立即抛出一个NullPointerException,而不是你访问car属性值时才返回一个错误。 3.可接受null的Optional Optional<Car> optCar = Optional.ofNullable(car); 如果car是null,那么得到的Optional对象就是个空对象。 两层Optional嵌套必须使用flatMap 如果你引用第三方库是需要序列化的,使用Optional可能会出错。 如果您返回的的是OptionalInt(基础类型)类型的对象,你就不能将其作为方法引用传递给另一个Optional对象的flatMap方法
-
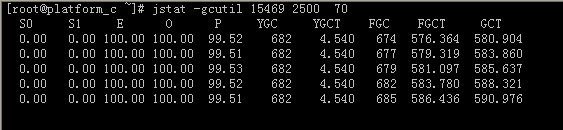
待运行稳定后GC之后用jmap抓取内存快照 1、待运行稳定后GC之后用jmap抓取内存快照 2、重新运行可能产生内存泄露的代码 3、GC到稳定之后再次抓取内存快照 4、对比2次快照就可知道了 java内存泄漏的定位与分析 1、为什么会发生内存泄漏 Java 如何检测内在泄漏呢?我们需要一些工具进行检测,并发现内存泄漏问题,不然很容易发生down机问题。 编写java程序最为方便的地方就是我们不需要管理内存的分配和释放,一切由jvm来进行处理,当java对象不再被应用时,等到堆内存不够用时,jvm会进行垃圾回收,清除这些对象占用的堆内存空间,如果对象一直被应用,jvm无法对其进行回收,创建新的对象时,无法从Heap中获取足够的内存分配给对象,这时候就会导致内存溢出。而出现内存泄露的地方,一般是不断的往容器中存放对象,而容器没有相应的大小限制或清除机制。容易导致内存溢出。 当服务器应用占用了过多内存的时候,如何快速定位问题呢?现在,Eclipse MAT的出现使这个问题变得非常简单。EclipseMAT是著名的SAP公司贡献的一个工具,可以在Eclipse网站下载到它,完全免费的。 要定位问题,首先你需要获取服务器jvm某刻内存快照。jdk自带的jmap可以获取内存某一时刻的快照,导出为dmp文件后,就可以用Eclipse MAT来分析了,找出是那个对象使用内存过多。 2、内存泄漏的现象: 常常地,程序内存泄漏的最初迹象发生在出错之后,在你的程序中得到一个OutOfMemoryError。这种典型的情况发生在产品环境中,而在那里,你希望内存泄漏尽可能的少,调试的可能性也达到最小。也许你的**测试**环境和产品的系统环境不尽相同,导致泄露的只会在产品中暴露。这种情况下,你需要一个低负荷的工具来监听和寻找内存泄漏。同时,你还需要把这个工具同你的系统联系起来,而不需要重新启动他或者机械化你的代码。也许更重要的是,当你做分析的时候,你需要能够同工具分离而使得系统不会受到干扰。 一个OutOfMemoryError常常是内存泄漏的一个标志,有可能应用程序的确用了太多的内存;这个时候,你既不能增加JVM的堆的数量,也不能改变你的程序而使得他减少内存使用。但是,在大多数情况下,一个OutOfMemoryError是内存泄漏的标志。一个解决办法就是继续监听GC的活动,看看随时间的流逝,内存使用量是否会增加,如果有,程序中一定存在内存泄漏。 3、发现内存泄漏 jstat -gc pid 可以显示gc的信息,查看gc的次数,及时间。 其中最后五项,分别是young gc的次数,young gc的时间,full gc的次数,full gc的时间,gc的总时间。 2.jstat -gccapacity pid 可以显示,VM内存中三代(young,old,perm)对象的使用和占用大小, 如:PGCMN显示的是最小perm的内存使用量,PGCMX显示的是perm的内存最大使用量, PGC是当前新生成的perm内存占用量,PC是但前perm内存占用量。 其他的可以根据这个类推, OC是old内纯的占用量。 3.jstat -gcutil pid 统计gc信息统计。 4.jstat -gcnew pid 年轻代对象的信息。 5.jstat -gcnewcapacity pid 年轻代对象的信息及其占用量。 6.jstat -gcold pid old代对象的信息。 7.stat -gcoldcapacity pid old代对象的信息及其占用量。 8.jstat -gcpermcapacity pid perm对象的信息及其占用量。 9.jstat -class pid 显示加载class的数量,及所占空间等信息。 10.jstat -compiler pid 显示VM实时编译的数量等信息。 11.stat -printcompilation pid 当前VM执行的信息。 一些术语的中文解释: S0C:年轻代中第一个survivor(幸存区)的容量 (字节) S1C:年轻代中第二个survivor(幸存区)的容量 (字节) S0U:年轻代中第一个survivor(幸存区)目前已使用空间 (字节) S1U:年轻代中第二个survivor(幸存区)目前已使用空间 (字节) EC:年轻代中Eden(伊甸园)的容量 (字节) EU:年轻代中Eden(伊甸园)目前已使用空间 (字节) OC:Old代的容量 (字节) OU:Old代目前已使用空间 (字节) PC:Perm(持久代)的容量 (字节) PU:Perm(持久代)目前已使用空间 (字节) YGC:从应用程序启动到采样时年轻代中gc次数 YGCT:从应用程序启动到采样时年轻代中gc所用时间(s) FGC:从应用程序启动到采样时old代(全gc)gc次数 FGCT:从应用程序启动到采样时old代(全gc)gc所用时间(s) GCT:从应用程序启动到采样时gc用的总时间(s) NGCMN:年轻代(young)中初始化(最小)的大小 (字节) NGCMX:年轻代(young)的最大容量 (字节) NGC:年轻代(young)中当前的容量 (字节) OGCMN:old代中初始化(最小)的大小 (字节) OGCMX:old代的最大容量 (字节) OGC:old代当前新生成的容量 (字节) PGCMN:perm代中初始化(最小)的大小 (字节) PGCMX:perm代的最大容量 (字节) PGC:perm代当前新生成的容量 (字节) S0:年轻代中第一个survivor(幸存区)已使用的占当前容量百分比 S1:年轻代中第二个survivor(幸存区)已使用的占当前容量百分比 E:年轻代中Eden(伊甸园)已使用的占当前容量百分比 O:old代已使用的占当前容量百分比 P:perm代已使用的占当前容量百分比 S0CMX:年轻代中第一个survivor(幸存区)的最大容量 (字节) S1CMX :年轻代中第二个survivor(幸存区)的最大容量 (字节) ECMX:年轻代中Eden(伊甸园)的最大容量 (字节) DSS:当前需要survivor(幸存区)的容量 (字节)(Eden区已满) TT:持有次数限制 MTT :最大持有次数限制 如果定位内存泄漏问题我一般使用如下命令: Jstat -gcutil15469 2500 70 [root@ssss logs]# jstat -gcutil 15469 1000 300 S0 S1 E O P YGC YGCT FGC FGCT GCT 0.00 1.46 26.54 4.61 30.14 35 0.872 0 0.000 0.872 0.00 1.46 46.54 4.61 30.14 35 0.872 0 0.000 0.872 0.00 1.46 47.04 4.61 30.14 35 0.872 0 0.000 0.872 0.00 1.46 65.19 4.61 30.14 35 0.872 0 0.000 0.872 0.00 1.46 67.54 4.61 30.14 35 0.872 0 0.000 0.872 0.00 1.46 87.54 4.61 30.14 35 0.872 0 0.000 0.872 0.00 1.46 88.03 4.61 30.14 35 0.872 0 0.000 0.872 1.48 0.00 5.56 4.62 30.14 36 0.874 0 0.000 0.874 1000 代表多久间隔显示一次, 100 代表显示一次。 S0 — Heap上的 Survivor space 0 区已使用空间的百分比 S1 — Heap上的 Survivor space 1 区已使用空间的百分比 E — Heap上的 Eden space 区已使用空间的百分比 O — Heap上的 Old space 区已使用空间的百分比 P — Perm space 区已使用空间的百分比 YGC — 从应用程序启动到采样时发生 Young GC 的次数 YGCT– 从应用程序启动到采样时 Young GC 所用的时间(单位秒) FGC — 从应用程序启动到采样时发生 Full GC 的次数 FGCT– 从应用程序启动到采样时 Full GC 所用的时间(单位秒) GCT — 从应用程序启动到采样时用于垃圾回收的总时间(单位秒) 如果有大量的FGC就要查询是否有内存泄漏的问题了,图中的FGC数量就比较大,并且执行时间较长,这样就会导致系统的响应时间较长,如果对jvm的内存设置较大,那么执行一次FGC的时间可能会更长。 如果为了更好的证明FGC对服务器性能的影响,我们可以使用**Java **visualVM来查看一下: 从上图可以发现执行FGC的情况,下午3:10分之前是没有FGC的,之后出现大量的FGC。 上图是jvm堆内存的使用情况,下午3:10分之前的内存回收还是比较合理,但是之后大量内存无法回收,最后导致内存越来越少,导致大量的full gc。 下面我们在看看大量full GC对服务器性能的影响,下面是我用loadrunner对我们项目进行压力测试相应时间的截图: 从图中可以发现有,在进行full GC后系统的相应时间有了明显的增加,点击率和吞吐量也有了明显的下降。所以java内存泄漏对系统性能的影响是不可忽视的。 3、定位内存泄漏 当然通过上面几种方法我们可以发现java的内存泄漏问题,但是作为一名合格的高级工程师,肯定不甘心就把这样的结论交给开发,当然这也的结论交给开发,开发也很难定位问题,为了更好的提供自己在公司的地位,我们必须给开发工程师提供更深入的测试结论,下面就来认识一下MemoryAnalyzer.exe。java内存泄漏检查工具利器。 首先我们必须对jvm的堆内存进行dump,只有拿到这个文件我们才能分析出jvm堆内存中到底存了些什么内容,到底在做什么? MemoryAnalyzer的用户我在这里就不一一说明了,我的博客里也有说明,下面就展示我测试的成功图: 其中深蓝色的部分就为内存泄漏的部分,java的堆内存一共只有481.5M而内存泄漏的部分独自占有了336.2M所以本次的内存泄漏很明显,那么我就来看看那个方法导致的内存泄漏: 从上图我们可以发现红线圈着的方法占用了堆内存的67.75%,如果能把这个测试结果交给开发,开发是不是应该很好定位呢。所以作为一名高级测试工程师,我们需要学习的东西太多。 虽然不确定一定是内存泄漏,但是可以准确的告诉开发问题出现的原因,有一定的说服力。
-
flyway与liquibase区别 Flyway 易于配置——你只需要指定一个文件夹位置,并遵循命名语法,如 V1__file.sql 等等。 基于 SQL,但你需要编写符合特定数据库引擎(如 MySQL、DB2 等)的正确语法。 基于 Java,因此添加自定义配置(如清理、执行等操作的配置)会更加容易。 Liquibase 需要一个主文件“changelog(变更日志)”来跟踪所有已执行的变更集。 基于 XML,所以你需要使用特定的 Liquibase 标签来创建 SQL 代码。这对于将代码迁移到不同的数据库引擎来说非常完美:你无需做任何更改,仅需数据库驱动程序告知 Liquibase 如何将 XML 标签转换为正确的 SQL 语法即可。 如果你使用 Liquibase 的 sql 标签,那么你将无法利用上述第二点的优势,在这种情况下,使用 Flyway 会更好。 Liquibase 提供了一个 JAR 文件,可以自动将现有数据库迁移为所有需要的 XML 文件,因此你无需手动处理这些文件,这非常有用。 现在,就需要你根据项目需求来决定使用哪个工具了,比如你是否需要在未来迁移到不同的数据库引擎等等。 梳理总结: Flyway:配置简单,基于 SQL 但依赖特定数据库语法,基于 Java 便于自定义配置。 Liquibase:依赖“changelog”文件跟踪变更,基于 XML 可方便跨数据库引擎迁移(不使用 sql 标签时),有自动将现有数据库转换为 XML 文件的工具,功能较为丰富。选择时需考虑项目未来是否有数据库引擎迁移需求等因素。