

🚀打造 AI 应用的核心利器
Langchain 是一个专为构建基于大语言模型(LLM)的应用而生的强大工具。它将 LLM、向量数据库、记忆机制、提示模板等模块进行了系统整合,大大简化了复杂 AI 应用的开发流程。本文将结合思维导图,对 Langchain 的核心能力做一个全面回顾,并介绍其生态工具 —— LangSmith,让我们能够对 LLM 应用进行高效调试与评估。
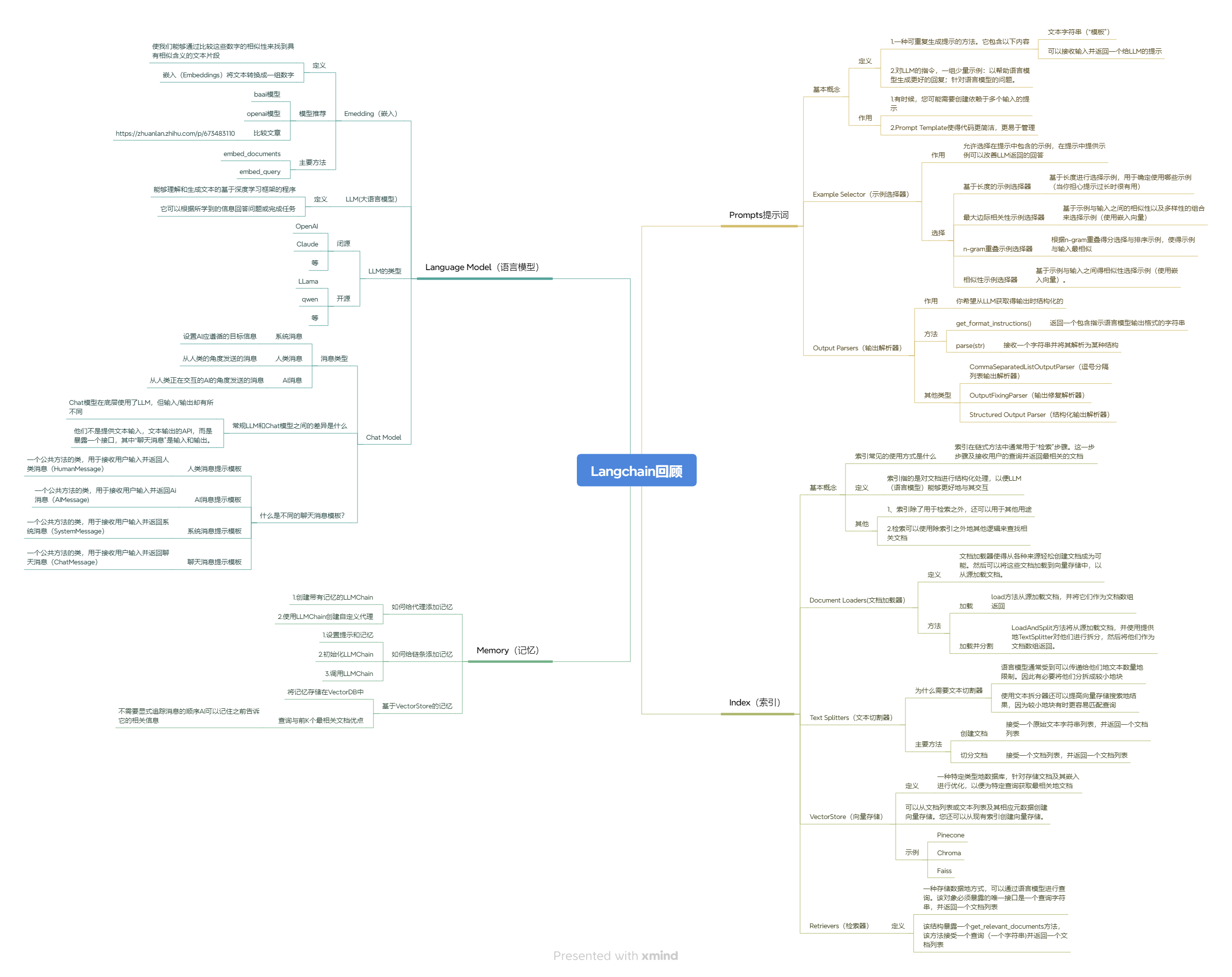
🧠 一、Language Model(语言模型)
Langchain 提供了对多种主流 LLM 的集成,包括:
- OpenAI、ChatGLM、Claude、LLaMA、Qwen 等主流模型
- 支持封装为 LLM、Chat Model 两种类型
- 提供如
HumanMessage、SystemMessage、AIMessage等统一结构,构建清晰上下文 - 支持 Embedding,集成了
text2vec、openai-embeddings等方案
🧾 二、Prompt 模块(提示词构建)
Langchain 封装了 Prompt 构建、示例选择、输出解析等功能:
- PromptTemplate:参数化构建提示词模板
- ExampleSelector:支持基于语义相似度选择 few-shot 示例
- Output Parsers:将 LLM 输出转为结构化数据,如 JSON、列表等
🧠 三、Memory(记忆模块)
用于保存对话历史、构建上下文感知的智能体(Agent)系统:
- 支持
ConversationBufferMemory、SummaryMemory、VectorStoreMemory等 - 能力包括短期记忆(会话)与长期记忆(知识)
📚 四、Index 模块(索引与检索)
Langchain 提供完整的 RAG 流程:
- 文档加载(Document Loaders):支持 txt、PDF、Notion、Web 等
- 文本切分(Text Splitters):如
RecursiveCharacterTextSplitter - 向量数据库(Vector Store):支持 FAISS、Chroma、Weaviate 等
- 检索器(Retriever):封装
.as_retriever()进行文档查询
🧪 五、LangSmith:Langchain 应用的调试和评估平台

LangSmith 是 Langchain 官方出品的可视化调试与监控平台,专门用于:
🔍 1. 调试链式调用过程
- 记录每一步链的调用细节
- 可视化展示 Prompt 输入、输出及 Token 使用情况
- 支持逐步调试复杂链(Chain)和 Agent 执行流程
📊 2. 性能评估与对比
- 定义多个 Prompt 模板进行 A/B 测试
- 自动记录响应时间、成功率、评分等指标
- 与 OpenAI Function、Tool 使用情况无缝集成
☁️ 3. 生产环境监控
- 监控 Agent 的运行行为、失败重试
- 接入自定义评分函数,对每次调用进行标注
✨ 总结一句话:
LangChain 让你快速构建 LLM 应用,LangSmith 让你安心上线并优化它。
🧩 六、应用场景示例
- 聊天机器人 / 客服系统
- 企业文档问答 / 私人知识库
- 表单解析 / 结构化信息提取
- 智能搜索系统(结合向量检索)
- Prompt 模板测试平台(结合 LangSmith)
一个比较完整的python demo实现
#langsmith 的key
#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
import os
os.environ['USER_AGENT'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
from langchain_community.llms import Ollama
from langchain import hub
from langchain.agents import create_openai_functions_agent
from langchain.agents import AgentExecutor
from langchain_core.messages import HumanMessage, AIMessage
from langchain_community.vectorstores import FAISS
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.tools.retriever import create_retriever_tool
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_ollama import OllamaEmbeddings
from langchain_ollama import OllamaLLM
# from langchain.pydantic_v1 import BaseModel, Field
from pydantic import BaseModel, Field
from fastapi import FastAPI
from typing import List
from langserve import add_routes
from langchain_core.messages import BaseMessage
### 1.加载检索器
loader = WebBaseLoader("https://docs.smith.langchain.com/user_guide")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
embeddings = OllamaEmbeddings(base_url="http://172.16.1.27:11434", model="nomic-embed-text:latest")
vector = FAISS.from_documents(docs,embeddings)
retriever = vector.as_retriever()
### 2. 创建工具
retriever_tool = create_retriever_tool(
retriever,
"langsmith_search",
"搜索与LangSmith相关的信息。有关LangSmith的任何问题,您必须使用此工具!",
)
search = TavilySearchResults()
tools = [retriever_tool, search]
### 3.创建代理人
# 加载模型
llama = OllamaLLM(model="llama3.2-vision:latest",base_url="http://172.16.1.27:11434")
# 获取要使用的提示 - 您可以修改此提示!
prompt = hub.pull("hwchase17/openai-functions-agent")
agent = create_openai_functions_agent(llama, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 4. 应用程序定义
app = FastAPI(
title="LangChain服务器",
version="1.0",
description="使用LangChain的可运行接口的简单API服务器",
)
# 5. 添加链路由
class Input(BaseModel):
input: str
chat_history: List[BaseMessage] = Field(
...,
extra={"widget": {"type": "chat","input":"location"}},
)
class Output(BaseModel):
output: str
add_routes(app, agent_executor.with_types(input_type=Input, output_type=Output), path="/agent")
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)
🧷 七、总结
Langchain 是构建大模型应用的主干框架,围绕核心模块 —— Prompt、Memory、Index、LLM,打通了从数据到生成的全链路。而 LangSmith 则作为配套工具,填补了 调试、测试、监控 的空白,帮助我们更好地构建可信的 AI 应用。
好的!既然你希望对比 Langchain + LangSmith 与其它技术方案,那我们可以从几个维度来做一个 横向对比分析,让你的博客不仅回顾 Langchain,还凸显它的优势和适用场景。
🧭 Langchain 与其他 LLM 应用框架的对比分析
在构建 LLM 应用时,除了 Langchain,还有不少热门的框架和工具,比如:
| 框架名称 | 核心特点 | 是否组件化 | 是否支持 Agent | 调试能力 | 主打场景 |
|---|---|---|---|---|---|
| Langchain | 模块化封装 Prompt、Memory、索引、Agent | ✅ | ✅ | ✅(搭配 LangSmith) | RAG、ChatBot、Agent |
| LlamaIndex | 强调数据索引能力,集成多种文档加载/拆分方式 | ✅ | ⚠️(基础 Agent 支持) | ❌ | 文档问答、知识库 |
| Haystack | 企业级搜索和问答,支持自定义 Pipeline | ✅ | ✅ | ✅(较重配置) | 企业内部搜索、QA |
| Autogen (MS) | 多 Agent 协作框架,适合任务分工 | ⚠️(较弱) | ✅(核心) | ❌(需配合日志) | Agent 协作系统 |
| Flowise | 可视化 Langchain,拖拽式搭建 | ✅(UI) | ✅(底层用 Langchain) | ✅(UI可视化) | 快速原型、低代码 |
🔍 详细维度分析
1. 开发体验
| 对比项 | Langchain | LlamaIndex | Haystack | Autogen | Flowise |
|---|---|---|---|---|---|
| 上手难度 | 中(模块较多) | 低(专注文档检索) | 中高(配置多) | 高(偏研究) | 低(拖拽) |
| 模块化 | ✅ | ✅ | ✅ | ⚠️ | ✅ |
| 类型支持 | 文档问答、对话、Agent | 文档问答 | QA Pipeline | 多智能体任务 | Chat/RAG |
📌 如果你要构建复杂的 AI 应用,Langchain 的模块化设计 + LangSmith 调试工具,开发体验更全面。
2. 文档问答能力(RAG 架构支持)
| 对比项 | Langchain | LlamaIndex | Haystack |
|---|---|---|---|
| 向量索引支持 | ✅(多种 VectorStore) | ✅ | ✅ |
| 文档加载丰富度 | ✅ | ✅ | ✅ |
| 拆分策略 | 丰富(Recursive、Token等) | 丰富 | 主要基于段落 |
| 多源融合 | ✅ | ✅ | ✅ |
| 检索方式灵活性 | 高(自定义 Retriever) | 中 | 中 |
📌 Langchain 与 LlamaIndex 都支持强大的 RAG,Langchain 更适合自定义 Agent 与对话流整合。
3. Agent 能力对比
| 对比项 | Langchain Agent | Autogen | Haystack |
|---|---|---|---|
| 多工具调用 | ✅ | ✅ | ✅(较少) |
| 工具链整合 | ✅(Tool/Toolkits) | ✅(需自建 Tool) | ⚠️ |
| 多 Agent 协作 | ✅(Router Chain) | ✅(核心能力) | ❌ |
| 日志追踪 | ✅(配合 LangSmith) | ❌ | ✅(基本) |
📌 如果你是搞 Agent 系统的,Autogen 适合多智能体协作研究,但 Langchain 更适合落地和定制。
4. 调试与监控(LangSmith 优势突显)
| 框架 | 是否支持可视化调试 | 是否支持运行监控 | 自定义评分支持 | 是否 SaaS 服务 |
|---|---|---|---|---|
| Langchain + LangSmith | ✅ | ✅ | ✅ | ✅(LangSmith 平台) |
| LlamaIndex | ❌ | ❌ | ❌ | ❌ |
| Haystack | 部分 | 部分 | 需手动配置 | ❌ |
| Autogen | ❌(手工打印) | ❌ | ❌ | ❌ |
📌 LangSmith 是目前 最适合 LLM 应用调试的可视化平台,对链条调用非常透明。
✅ 总结:我该选谁?
- 你想快速构建实用型 AI 应用(问答、客服、Agent):用 Langchain + LangSmith
- 你只想搞定文档问答系统:可以考虑 LlamaIndex
- 你有企业级搜索需求:考虑 Haystack
- 你研究智能体协作:玩玩 Autogen
- 你是产品经理或低代码开发者:试试 Flowise
评论