

服务管理软件相关知识
1. 概述
一个支持多数据中心下,分布式高可用的服务管理软件,具备服务发现和配置共享功能。以consul为例,consul支持健康检查,允许存储键值对,一致性协议采用Raft算法保证服务高可用,成员管理和消息广播采用GOSSIP协议,支持ACL访问控制。
ACL技术在路由器中广泛采用,是基于包过滤的流控制技术,控制列表以源地址、目的地址及端口号为基本检查元素,规定符合条件的数据包是否允许通过。
gossip是p2p协议,去中心化,模拟人类传播谣言行为,有种子节点,种子节点每秒随机向其他节点发送自己的节点列表及要传播的消息,新加入节点能很快被全网知晓。
服务注册是一个服务将其位置信息在“中心注册节点”注册的过程,一般会注册主机IP地址、端口号,有时还有服务访问认证信息、使用协议、版本号及环境细节信息。
服务发现可让应用或组件发现其运行环境及其他应用或组件的信息,用户配置服务发现工具可分离实际容器与运行配置,常见配置信息有ip、端口号、名称等。当服务存在于多个主机节点上时,传统用静态配置实现服务信息注册,复杂系统中,为避免服务中断,动态的服务注册和发现很重要。
相关开源项目有Zookeeper,Doozer,Etcd等强一致性项目,主要用于服务间协调,也可用于服务注册。
强一致性协议是按照某一顺序串行执行存储对象读写操作,更新存储对象后,后续访问总是读到最新值,常见实现方法有主从同步复制和quorum复制等。
参考链接:http://blog.csdn.net/shlazww/article/details/38736511
2. consul的具体应用场景
- docker、coreos 实例的注册与配置共享
- vitess集群
- SaaS应用的配置共享
- 与confd服务集成,动态生成nignx与haproxy配置文件
3. 优势
- 使用Raft算法保证一致性,比poxes算法更直接,zookeeper采用poxes算法。 Raft将过程分为leader election,log replication和commit(safety)三个阶段,每个server有leader,follower,candidate三种状态,正常时只有一个leader,其他为follower,server间通过RPC消息通信,follower不主动发起RPC,leader和candidate(选主时)主动发起。先选一个leader负责管理日志复制,leader接收log entries并复制给其他机器,决定何时将日志应用于状态机,leader可决定新entries位置,数据从leader流向其他机器,leader故障或失联会选举新leader。 参考链接:http://www.jdon.com/artichect/raft.html http://blog.csdn.net/cszhouwei/article/details/38374603
- 支持多数据中心,内外网服务用不同端口监听,避免单点故障,zookeeper等不支持多数据中心功能。
- 支持健康检查
- 提供web界面
- 支持http协议与dns协议接口
4. 安装(mac os x)
通过工具安装:
brew cask install consul
brew cask安装方便,参考链接:http://brew.sh/#install
5. 测试 与 运行consul
- 测试:
consul
- 以服务端形式运行consul:
consul agent -server -bootstrap-expect 1 -data-dir /tmp/consul
- 查看consul服务节点:
consul members
- 将http请求发给consul server:
$ curl localhost:8500/v1/catalog/nodes
[{"Node":"Armons-MacBook-Air","Address":"10.1.10.38"}]
6. 注册服务
- 创建文件夹
/etc/consul.d,.d表示里面有许多配置文件。 - 将服务配置文件写入文件夹内,如:
$ echo '{"service": {"name": "web", "tags": ["rails"], "port": 80}}' >/etc/consul.d/web.json
- 重启consul,并将配置文件的路径给consul:
$ consul agent -server -bootstrap-expect 1 -data-dir /tmp/consul -config-dir /etc/consul.d
- 查询ip和端口:
- DNS方式:
dig @127.0.0.1 -p 8600 web.service.consul SRV
- **Http方式**:
curl http://localhost:8500/v1/catalog/service/web
- 更新:通过http api能对service配置文件增删改查,更新完成后,可通过signup命令生效。
7. 组建集群
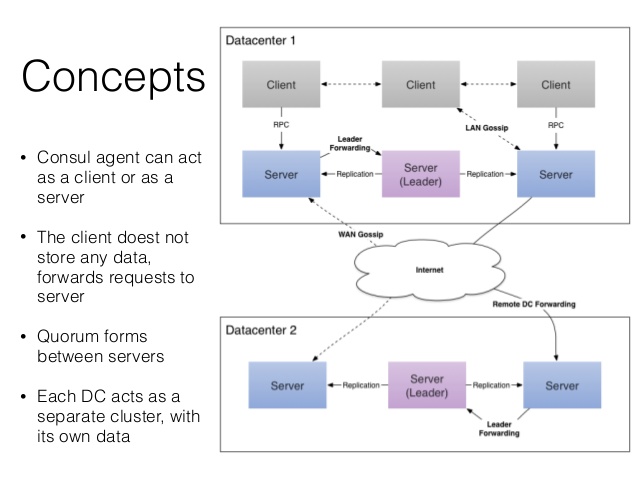 一个consul agent是独立程序,长时间运行的守护进程,运行在concul集群每个节点上。启动一个consul agent是孤立node,想知道集群其他节点需加入集群。
一个consul agent是独立程序,长时间运行的守护进程,运行在concul集群每个节点上。启动一个consul agent是孤立node,想知道集群其他节点需加入集群。
agent有server与client两种模式,server模式负责一致性工作,保证一致性和可用性(部分失败时),响应RPC,同步数据到其他节点代理;client模式与server通信,转发RPC到服务的代理agent,仅保存少量自身状态,轻量化、无状态。
agent除设置server/client模式、数据路径外,最好设置node的名称和ip。
LAN gossip pool包含同一局域网内所有节点(server与client),基本位于同一个数据中心DC;WAN gossip pool一般仅包含server,跨越多个DC数据中心,通过互联网或广域网通信。Leader服务器负责所有RPC请求查询并响应,其他服务器收到client的RPC请求会转发到leader服务器。
安装vagrant,初始化vagrant环境:
sudo vagrant init
启动一个虚拟node节点:
vagrant up
查看vm启动状态(包括vm名称):
vagrant status
登陆到vm节点:
vagrant ssh vm_name
bootstrap模式下node可指定自己为leader,无需选举,然后依次启动其他server(非bootstrap模式),最后停止第一个server的bootstrap模式,重新以非bootstrap模式启动,server间自动选举leader。
分别在两个vm上配置consul agent,如:
$ vagrant ssh n1
vagrant@n1:~$ consul agent -server -bootstrap-expect 1 \
-data-dir /tmp/consul -node=agent-one -bind=172.20.20.10
$ vagrant ssh n2
vagrant@n2:~$ consul agent -data-dir /tmp/consul -node=agent-two \
-bind=172.20.20.11
此时,应用consul members查询,两个consul node独立无关联。
将client加入到server集群中:
vagrant@n1:~$ consul join 172.20.20.11
再用consul members查询,会发现多了一个node节点。
手动加入新节点麻烦,较好方法是将节点配置成自动加入集群:
consul agent -atlas-join \
-atlas=ATLAS_USERNAME/infrastructure \
-atlas-token="YOUR_ATLAS_TOKEN"
离开集群:
ctrl+c,或者 kill 指定的agent进程,就可以将相关的agent推出集群
让consul运行起来,consul server推荐3~5个,先启动一台server并配置到bootstrap模式,再依次启动其他server(非bootstrap模式),最后停止第一个server的bootstrap模式,重新以非bootstrap模式启动,server间自动选举leader。
参考链接:http://www.bubuko.com/infodetail-800623.html
8. 查询健康状态
- 应用http接口查询失败的节点:
curl http://localhost:8500/v1/health/state/critical
- 对于失败的节点,应用DNS查询时无法拿到返回结果:
dig @127.0.0.1 -p 8600 web.service.consul
9. K/V存储
- 查询所有K/V:
curl -v http://localhost:8500/v1/kv/?recurse
- 保存键为web/key2, flags 为42, 值为true的记录:
curl -X PUT -d 'test' http://localhost:8500/v1/kv/web/key2?flags=42
true
- 删除记录:
curl -X DELETE http://localhost:8500/v1/kv/web/sub?recurse
- 更新值:
curl -X PUT -d 'newval' http://localhost:8500/v1/kv/web/key1?cas=97
true
- 更新index:
curl "http://localhost:8500/v1/kv/web/key2?index=101&wait=5s"
结果:[{"CreateIndex":98,"ModifyIndex":101,"Key":"web/key2","Flags":42,"Value":"dGVzdA=="}]
更详细的consul命令详解:http://m.oschina.net/blog/353392
10. 断电恢复outage recover
当有一台服务器不可用时,处理方法:
- 对服务器进恢复,然后重新上线
- 用新服务器,替代旧的consul服务器(这两种方式都需要将服务器ip与原来的ip相同)
- 添加新的服务器,ip无需与原来相同,步骤:停掉所有的consul服务器,将损坏的服务器ip从raft/peer.json中移除,重启其他服务器,并将新的服务器加入集群。
11. 其他
服务发现是怎么工作呢?
每一个服务发现工具都会提供一套API,使得组件可以用其来设置或搜索数据。正是如此,对于每一个组件,服务发现的地址要么强制编码到程序或容器内部,要么在运行时以参数形式提供。通常来说,发现服务用键值对形式实现,采用标准http协议交互。
服务发现门户的工作方式是:当每一个服务启动上线之后,他们通过发现工具来注册自身信息。它记录了一个相关组件若想使用某服务时的全部必要信息。例如,一个MySQL数据库服务会在这注册它运行的ip和端口,如有必要,登录时的用户名和密码也会留下。
当一个服务的消费者上线时,它能够在预设的终端查询该服务的相关信息。然后它就可以基于查到的信息与其需要的组件进行交互。负载均衡就是一个很好的例子,它可以通过查询服务发现得到各个后端节点承受的流量数,然后根据这个信息来调整配置。
这可将配置信息从容器内拿出。一个好处是可以让组件容器更加灵活,并不受限于特定的配置信息。另一个好处是使得组件与一个新的相关服务实例交互时变得简单,可以由管理工具动态进行调整配置。
评论